快速微调行业模型,解锁专属AI生产力
📌 场景概述
企业或研究机构往往拥有结构化或非结构化的领域知识数据,如医��疗病历、法律法规、金融研报等。这些数据具有强行业特征,直接使用通用大模型可能效果不佳。通过 CSGHub 提供的模型与数据托管能力,用户可快速完成训练数据准备,并以开源模型为基础,微调出更契合业务的行业大模型。
- 客户类型:创业公司 / 行业研究机构
- 目标:基于行业语料,训练一个贴合自身业务的专属语言模型,用于问答系统、知识提取、文档生成等任务。
🧭 操作流程
1. 创建训练数据集
- 登录传神社区,创建新的训练数据集。数据集可以归属于个人或团队。
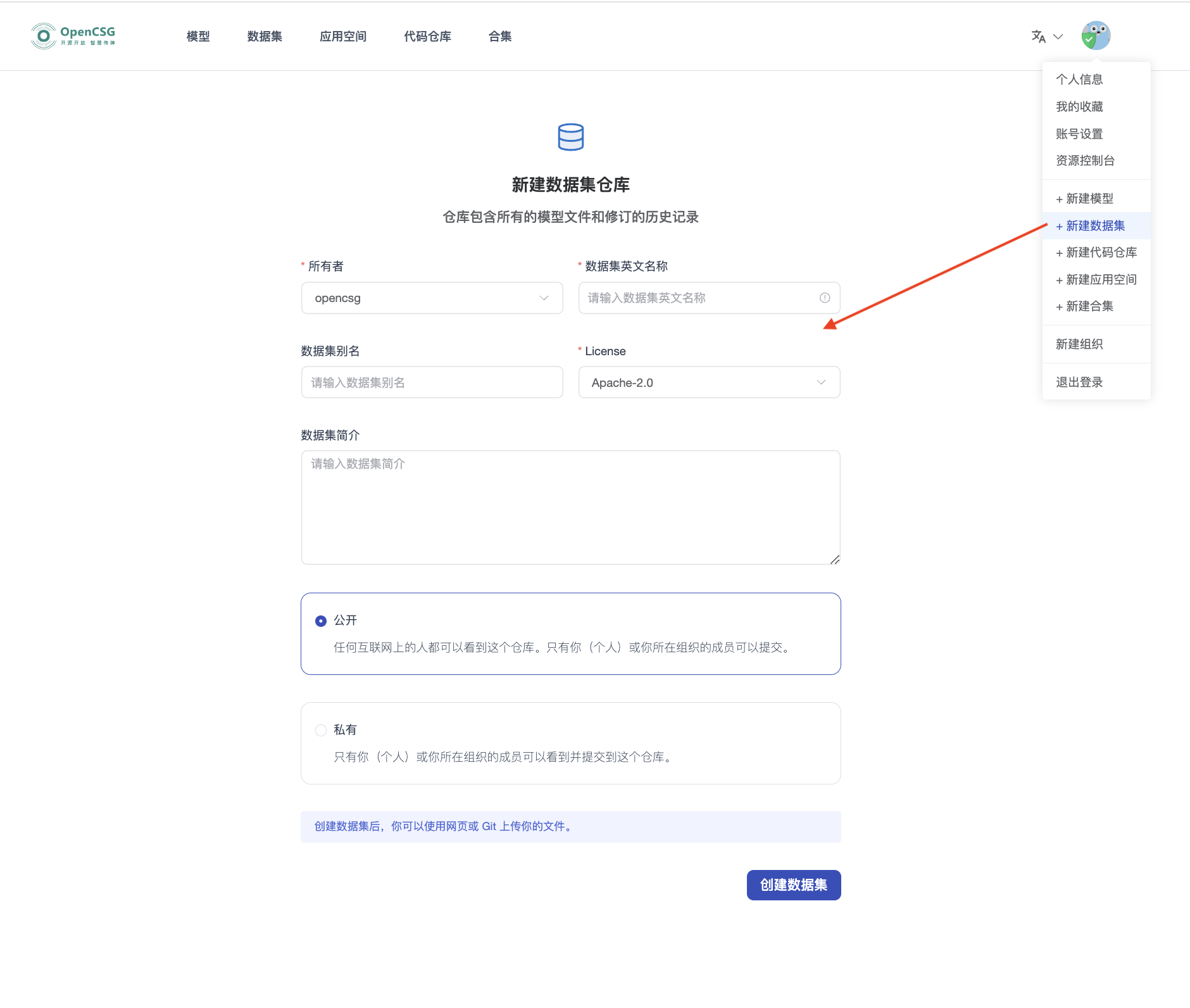
- 若需多人协作管理,可创建组织并邀请项目成员加入。
2. 上传行业语料
- 上传训练语料,格式支持
.jsonl、.txt等常��见格式,适配监督微调或其他任务需求。可添加描述和标签,便于后续管理与复用。 - 传神社区提供了多种数据集上传方式
3. 选择基础模型
- 进入模型列表,浏览并选择适合任务的开源基础模型(如 DeepSeek、Qwen、Baichuan、InternLM 等),查看模型详情和许可协议。
- 也可通过模型详情页右侧的模型树功能,查看模型的来源和衍生关系,选择合适的模型进行微调。
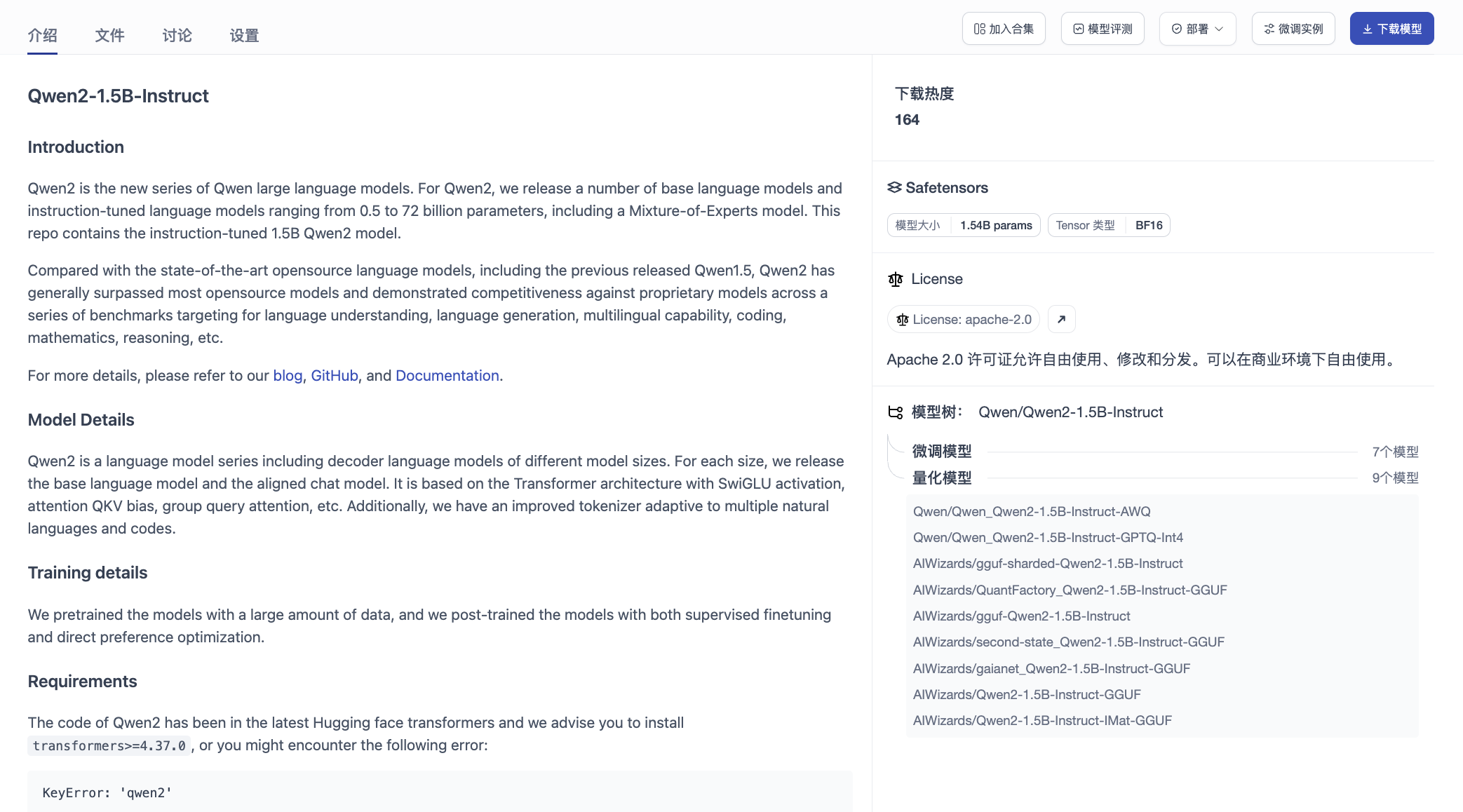
4. 创建微调任务
- 在所选模型详情页中点击【微调实例】,填写任务名称、选择训练数据集,配置训练参数(如学习率、batch size、训练轮数等),并一键启动训练任务。
- 传神社区提供了多种模型微调框架,查看模型微调框架介绍文档,根据不同场景来选用。
5. 完成模型训练发布版本
- 训练完成后,可通过命令行工具或 Web UI 将训练好的模型上传至个人或组织的模型仓库,并发布为一个新版本。支持通过标签、说明文档等进行版本管理。
🌟 最终效果
- 获得一个经过微调的行业语言模型,显著提升对行业术语、语境的理解能力;
- 支持在私有化环境中部署模型,用于问答机器人、文档生成等多种应用;
- 微调流程简化,零基础团队也可通过 Web 界面完成全流程;
- 模型版本清晰可控,支持回滚与升级,方便持续优化。