Data Processing Algorithm Templates
DataFlow provides a variety of built-in data processing templates, including Basic Data Processing, Advanced Data Processing, and Data Augmentation templates. The platform will continue to expand with new templates to enhance data processing capabilities.
Users can also create custom templates or modify existing ones to build personalized data processing pipelines tailored to specific needs.
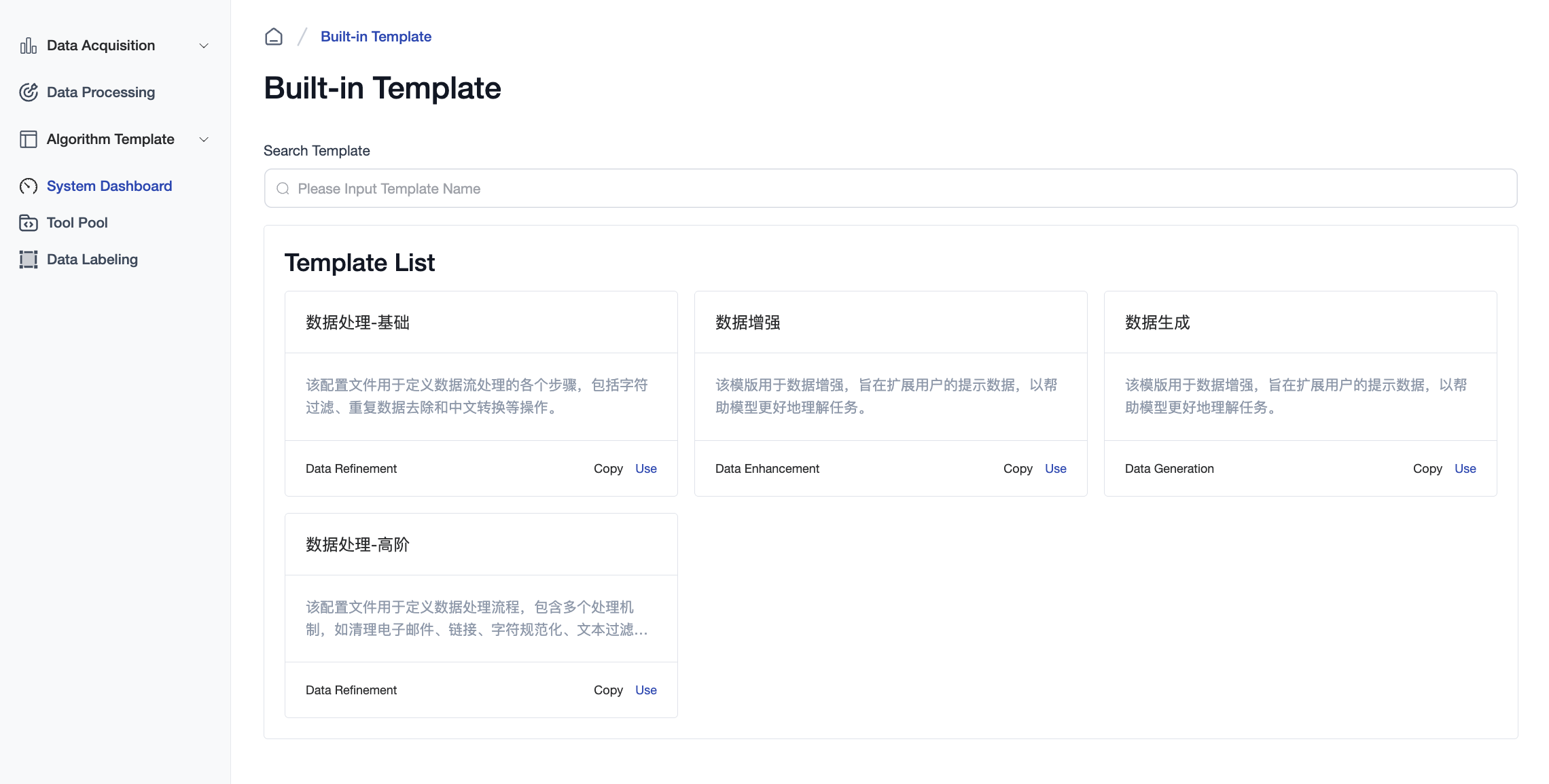
Creating a New Algorithm Template
-
Modify a Built-in Template: Click
Copyon a built-in template card to open the template creation page. -
Create a Template from Scratch: Click
Custom Templateitem, nav to theCustom Templatepage, and click the+ Createbutton.
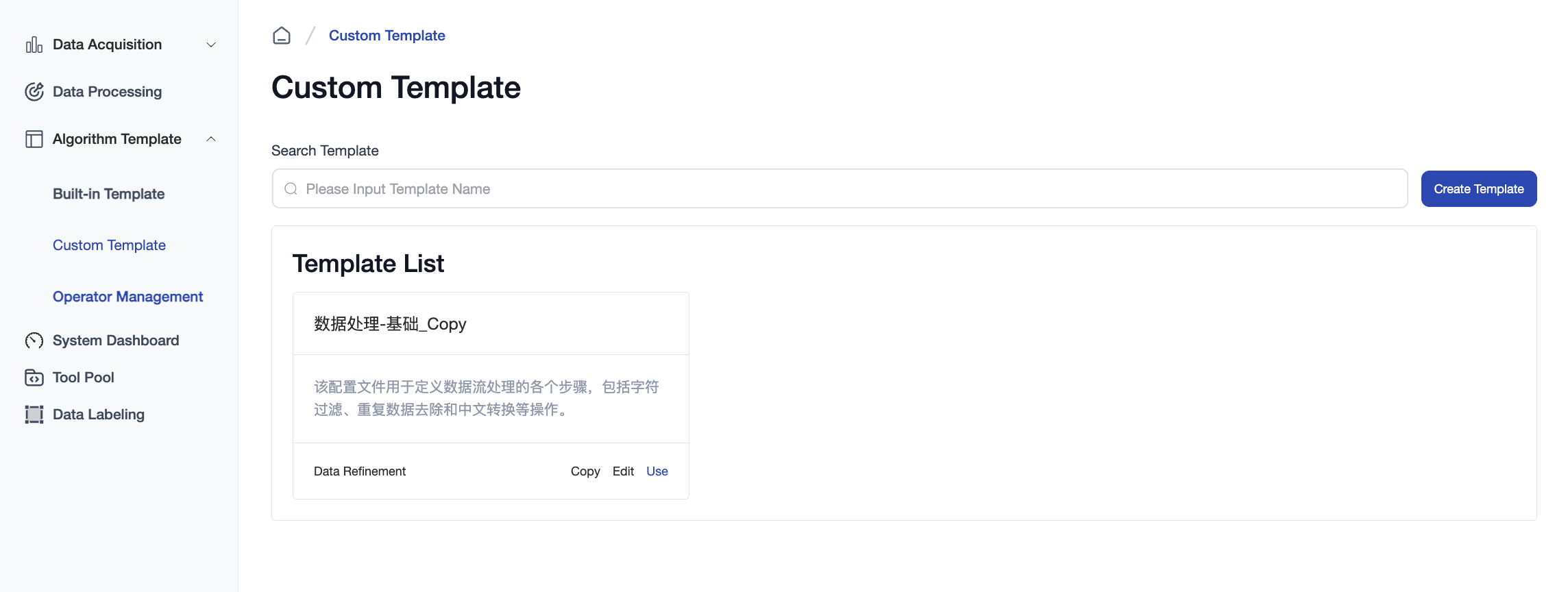
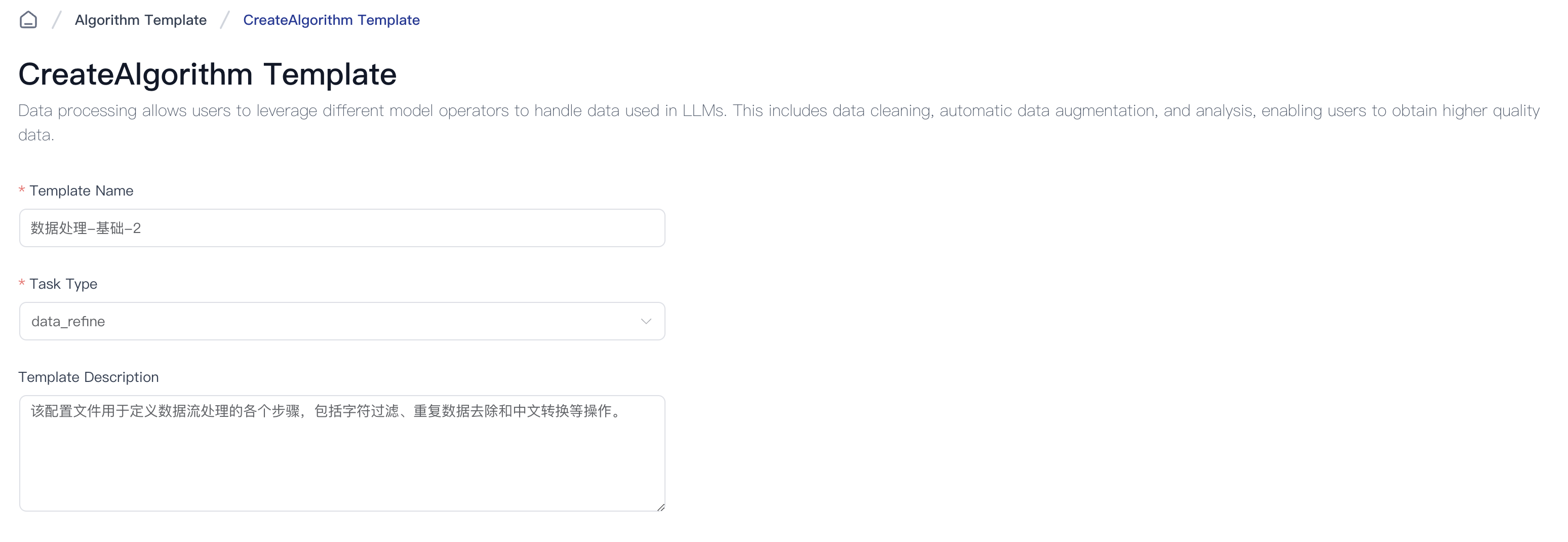
Fill in the Template Name, Task Type, and Template Description fields, and select the necessary operators and their execution order.
Note: Some operators require parameter configuration.
Once configured, click Creation Completed to start using the new template for data processing tasks.
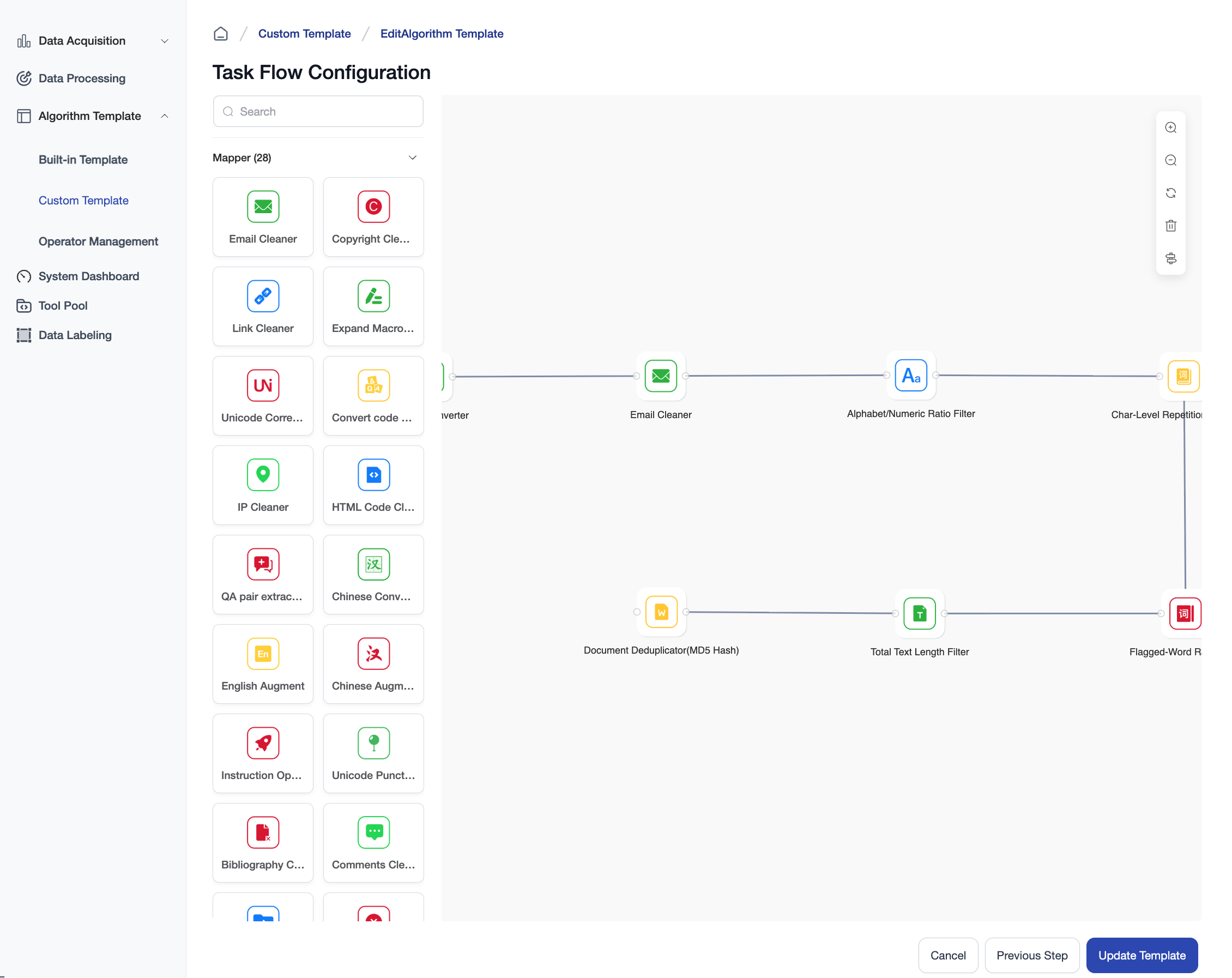
Operators Supported by the Platform
| ID | Name | Type | Description |
|---|---|---|---|
| chinese_convert_mapper | Chinese Converter | Mapper | Mapper to convert Chinese between Traditional Chinese, Simplified Chinese and Japanese Kanji. |
| clean_copyright_mapper | Copyright Cleaner | Mapper | Mapper to clean copyright comments at the beginning of the text samples. |
| clean_email_mapper | Email Cleaner | Mapper | Mapper to clean email in text samples. |
| clean_html_mapper | HTML Code Cleaner | Mapper | Mapper to clean html code in text samples. |
| clean_ip_mapper | IP Cleaner | Mapper | Mapper to clean ipv4 and ipv6 address in text samples. |
| clean_links_mapper | Link Cleaner | Mapper | Mapper to clean links like http/https/ftp in text samples. |
| expand_macro_mapper | Expand Macro Definitions | Mapper | Mapper to expand macro definitions in the document body of Latex samples. |
| generate_code_qa_pair_mapper | Convert code to QA pair | Mapper | Mapper to generate new instruction data based on code. |
| extract_qa_mapper | QA pair extractor | Mapper | Mapper to extract question and answer pair from text samples. |
| fix_unicode_mapper | Unicode Corrector | Mapper | Mapper to fix unicode errors in text samples. |
| nlpaug_en_mapper | English Augment | Mapper | Mapper to simply augment samples in English based on nlpaug library. |
| nlpcda_zh_mapper | Chinese Augment | Mapper | Mapper to simply augment samples in Chinese based on nlpcda library. |
| optimize_instruction_mapper | Instruction Optimizer | Mapper | Mapper to optimize instruction. |
| punctuation_normalization_mapper | Unicode Punctuations Normalizor | Mapper | Mapper to normalize unicode punctuations to English punctuations in text samples. |
| remove_bibliography_mapper | Bibliography Cleaner | Mapper | Mapper to remove bibliography at the end of documents in Latex samples. |
| remove_comments_mapper | Comments Cleaner | Mapper | Mapper to remove comments in different kinds of documents. Only support 'tex' for now. |
| remove_header_mapper | Remove Header | Mapper | Mapper to remove headers at the beginning of documents in Latex samples. |
| remove_long_words_mapper | Long Words Cleaner | Mapper | Mapper to remove long words within a specific range. |
| remove_non_chinese_character_mapper | Non Chinese Cleaner | Mapper | Mapper to remove non chinese Character in text samples. |
| remove_repeat_sentences_mapper | Sentence De-duplication | Mapper | Mapper to remove repeat sentences in text samples. |
| remove_specific_chars_mapper | Specific Chars Cleaner | Mapper | Mapper to clean specific chars in text samples. now support: ◆●■►▼▲▴∆▻▷❖♡□ |
| remove_table_text_mapper | Table Texts Cleaner | Mapper | Mapper to remove table texts from text samples. Regular expression is used to remove tables in the range of column number of tables. |
| remove_words_with_incorrect_substrings_mapper | Incorrect Substring Cleaner | Mapper | Mapper to remove words with incorrect substrings. |
| replace_content_mapper | Content Replacement | Mapper | Mapper to replace all content in the text that matches a specific regular expression pattern with a designated replacement string. |
| sentence_split_mapper | Sentence Spliter | Mapper | Mapper to split text samples to sentences. |
| whitespace_normalization_mapper | Whitespace Normalizor | Mapper | Mapper to normalize different kinds of whitespaces to whitespace ' ' (0x20) in text samples. |
| alphanumeric_filter | Alphabet/Numeric Ratio Filter | Filter | Filter to keep samples with alphabet/numeric ratio within a specific range. |
| average_line_length_filter | Average Line Length Filter | Filter | Filter to keep samples with average line length within a specific range. |
| character_repetition_filter | Char-Level Repetition Ratio Filter | Filter | Filter to keep samples with char-level n-gram repetition ratio within a specific range. |
| flagged_words_filter | Flagged-Word Ratio Filter | Filter | Filter to keep samples with flagged-word ratio less than a specific max value. |
| language_id_score_filter | Specific Language Filter | Filter | Filter to keep samples in a specific language with confidence score larger than a specific min value. |
| maximum_line_length_filter | Maximum Line Length Filter | Filter | Filter to keep samples with maximum line length within a specific range. |
| perplexity_filter | Perplexity Score Filter | Filter | Filter to keep samples with perplexity score less than a specific max value. |
| special_characters_filter | Special-Char Ratio Filter | Filter | Filter to keep samples with special-char ratio within a specific range. |
| specified_field_filter | Specified Field Information Filter | Filter | Filter based on specified field information. If the specified field information in the sample is not within the specified target value, the sample will be filtered. |
| specified_numeric_field_filter | Specified Numeric Field Filter | Filter | Filter based on specified numeric field information. If the specified numeric information in the sample is not within the specified range, the sample will be filtered. |
| stopwords_filter | Stopword Ratio Filter | Filter | Filter to keep samples with stopword ratio larger than a specific min value. |
| suffix_filter | Specified Suffix Filter | Filter | Filter to keep samples with specified suffix. |
| text_action_filter | Texts Contain Actions Filter | Filter | Filter to keep texts those contain actions in the text.. |
| text_entity_dependency_filter | Texts Containing Entities Filter | Filter | Identify the entities in the text which are independent with other token, and filter them. The text containing no entities will be omitted. |
| text_length_filter | Total Text Length Filter | Filter | Filter to keep samples with total text length within a specific range. |
| token_num_filter | Total Token Number Filter | Filter | Filter to keep samples with total token number within a specific range. |
| word_repetition_filter | Word-Level Repetition Ratio Filter | Filter | Filter to keep samples with word-level n-gram repetition ratio within a specific range. |
| words_num_filter | Total Words Number Filter | Filter | Filter to keep samples with total words number within a specific range. |
| document_deduplicator | Document Deduplicator(MD5 Hash) | Deduplicator | Deduplicator to deduplicate samples at document-level using exact matching. |
| Using md5 hash to deduplicate samples. | |||
| document_minhash_deduplicator | Document Deduplicator(MinHashLSH) | Deduplicator | Deduplicator to deduplicate samples at document-level using MinHashLSH. |
| Different from simhash, minhash is stored as bytes, so they won't be kept in the final dataset. | |||
| document_simhash_deduplicator | Document Deduplicator(SimHash) | Deduplicator | Deduplicator to deduplicate samples at document-level using SimHash. |
| frequency_specified_field_selector | Sorted Frequency Selector | Selector | Selector to select samples based on the sorted frequency of specified field. |
| random_selector | Random Selector | Selector | Selector to random select samples. |
| range_specified_field_selector | Sorted Range Selector | Selector | Selector to select a range of samples based on the sorted specified field value from smallest to largest. |
| topk_specified_field_selector | Top Samples Selector | Selector | Selector to select top samples based on the sorted specified field value. |
| annotate_edu_train_bert_scorer_mapper | Educational Evaluation Scoring | Mapper | Uses the Qwen2.5-14B model to evaluate the educational value of selected text and assign a score from 0 to 5. |
| text_high_score_filter | High-Score Data Filtering | Filter | Filters out data with scores greater than 3. |
| text_bloom_filter | Bloom Filter Deduplication | Filter | Removes duplicates in the dataset using a Bloom filter. |
| make_cosmopedia_mapper | Stylized Data Synthesis | Mapper | Reads seed data, treats each seed as a topic, and uses a prompt template to specify style and genre. The data is then passed to a vLLM model to generate synthetic data in the specified style. |
| pipeline_magpie_zh_mapper | Similarity-Based Deduplication | Mapper | Uses the DeepSeek-v2.5 or Qwen2.5 model with manually designed system prompts for multiple tasks to generate multi-turn dialogue data. |
| gather_generated_data_filter | Data Aggregation and Cleaning | Filter | Aggregates the generated data from the previous step, performs initial cleaning, and saves it as a file. |
| encode_and_get_nearest_mapper | Sample Encoding and Nearest Search | Mapper | Uses the gte-large-zh model to encode the first user_query in each dialogue into an embedding vector, then searches for the nearest sample based on cosine similarity. |
| dedup_and_save_deduplicator_deduplicator | Multi-Turn Dialogue Deduplication | Deduplicator | Deduplicates results by keeping only one random entry from each similarity group, and saves them into different files by task type. |