Data Processing Task
This tutorial uses the sample dataset file data_sample.jsonl to demonstrate DataFlow’s data processing capabilities. Supported dataset formats include: jsonl, json, parquet, csv, txt, tsv, and jsonl.zst.
DataFlow Entry Points
DataFlow offers two entry points on the CSGHub platform for efficient data management:
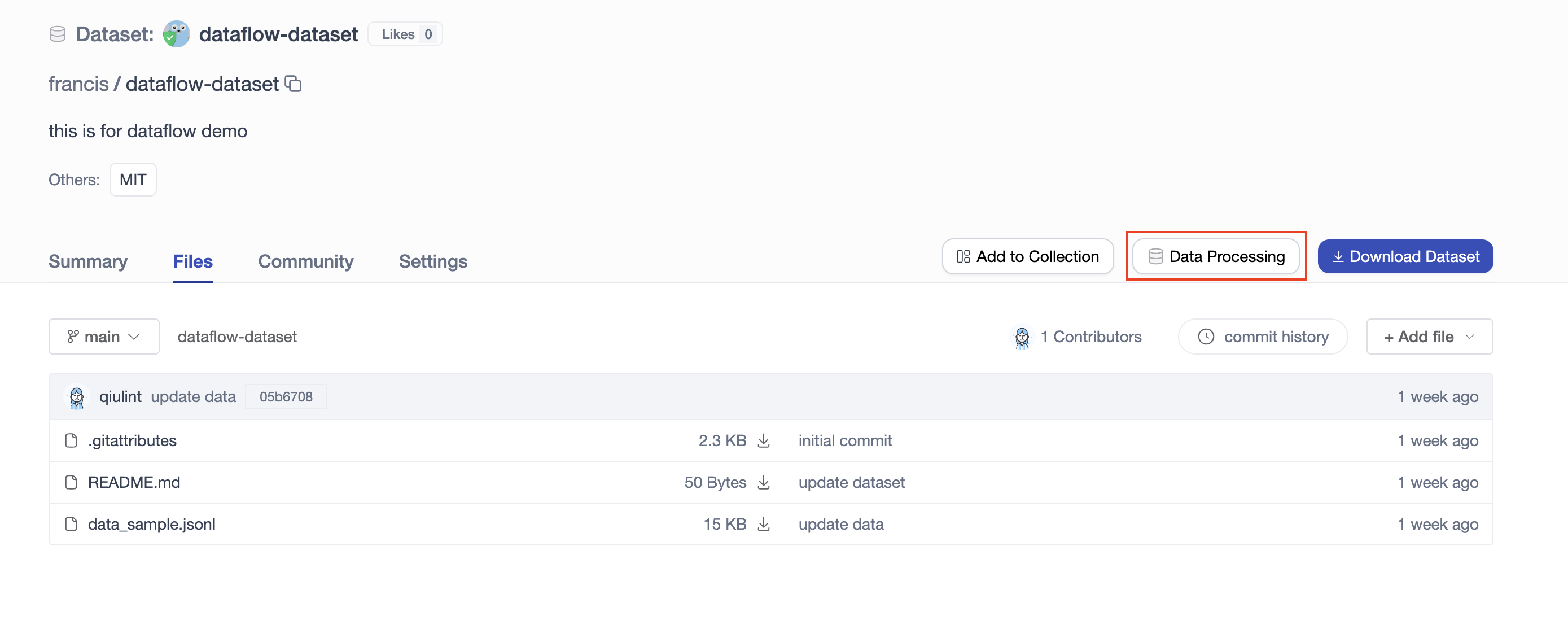
- Entry 1:
In the
dataflow-datasetrepository and clickData Processingbutton to create a task.Note: Make sure the dataset is under your personal repository; otherwise, the "Data Processing" button will not be available.
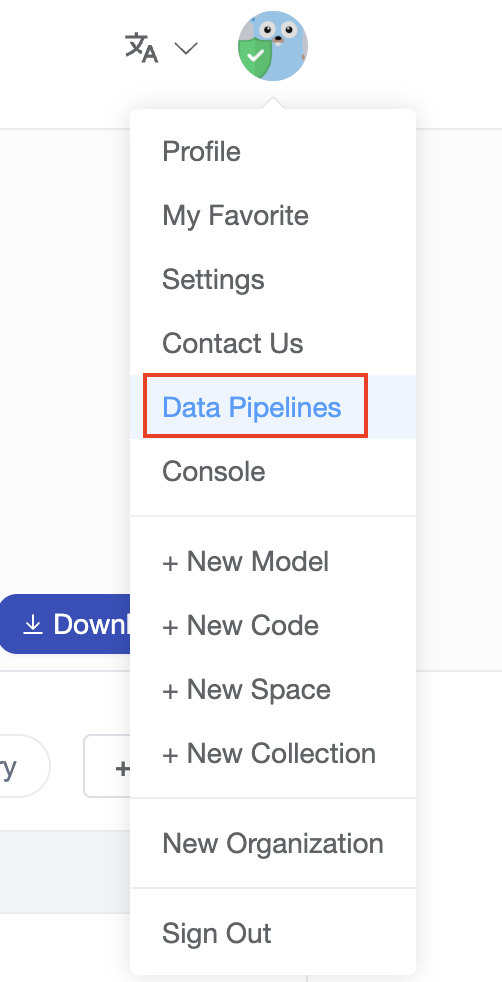
- Entry 2:
Access DataFlow from the
Data Pipelinesoption under your avatar.
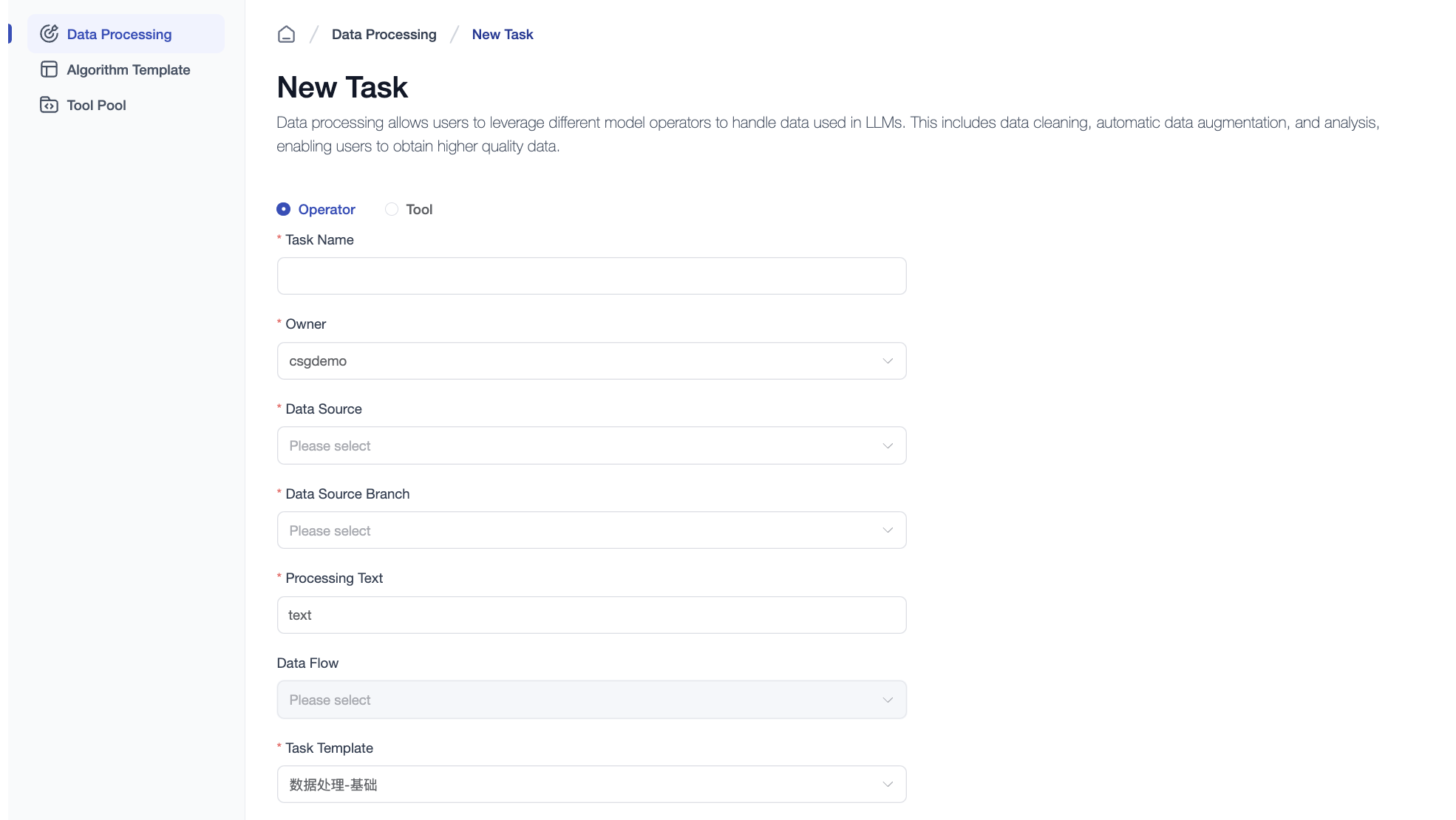
Creating a Data Processing Task
When entering through Entry 1, the Data Source field is pre-filled. If using Entry 2, you will need to select it manually.
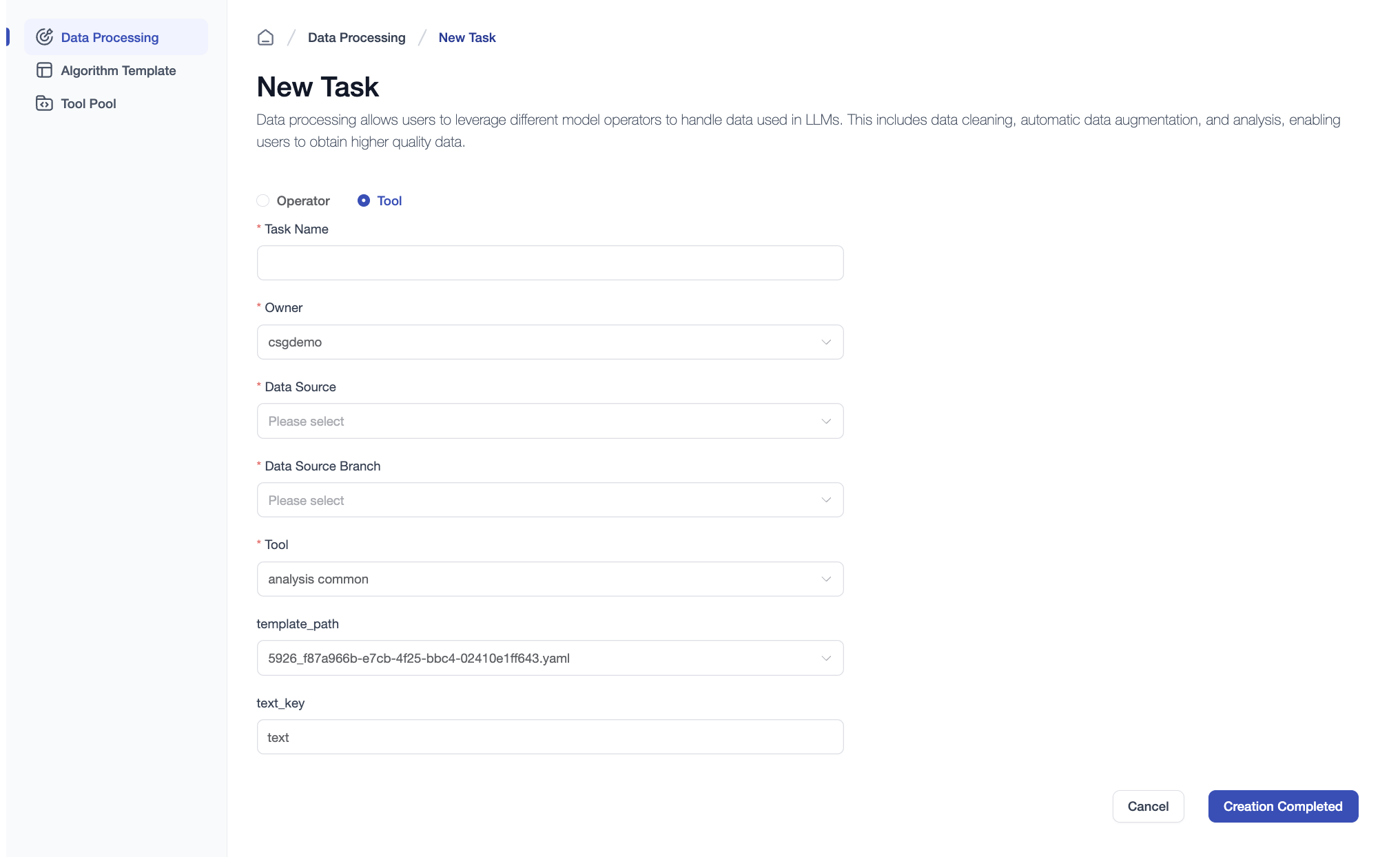
There are two types of data processing tasks: operator-based and tool-based.
-
Operator-based tasks Fill in the task name, data source and branch, then select an algorithm template. You can also adjust operator parameter settings as needed.
-
Tool-based tasks Fill in the task name, data source and branch, then select a tool. Different tools require different parameter configurations; you can adjust them as needed.
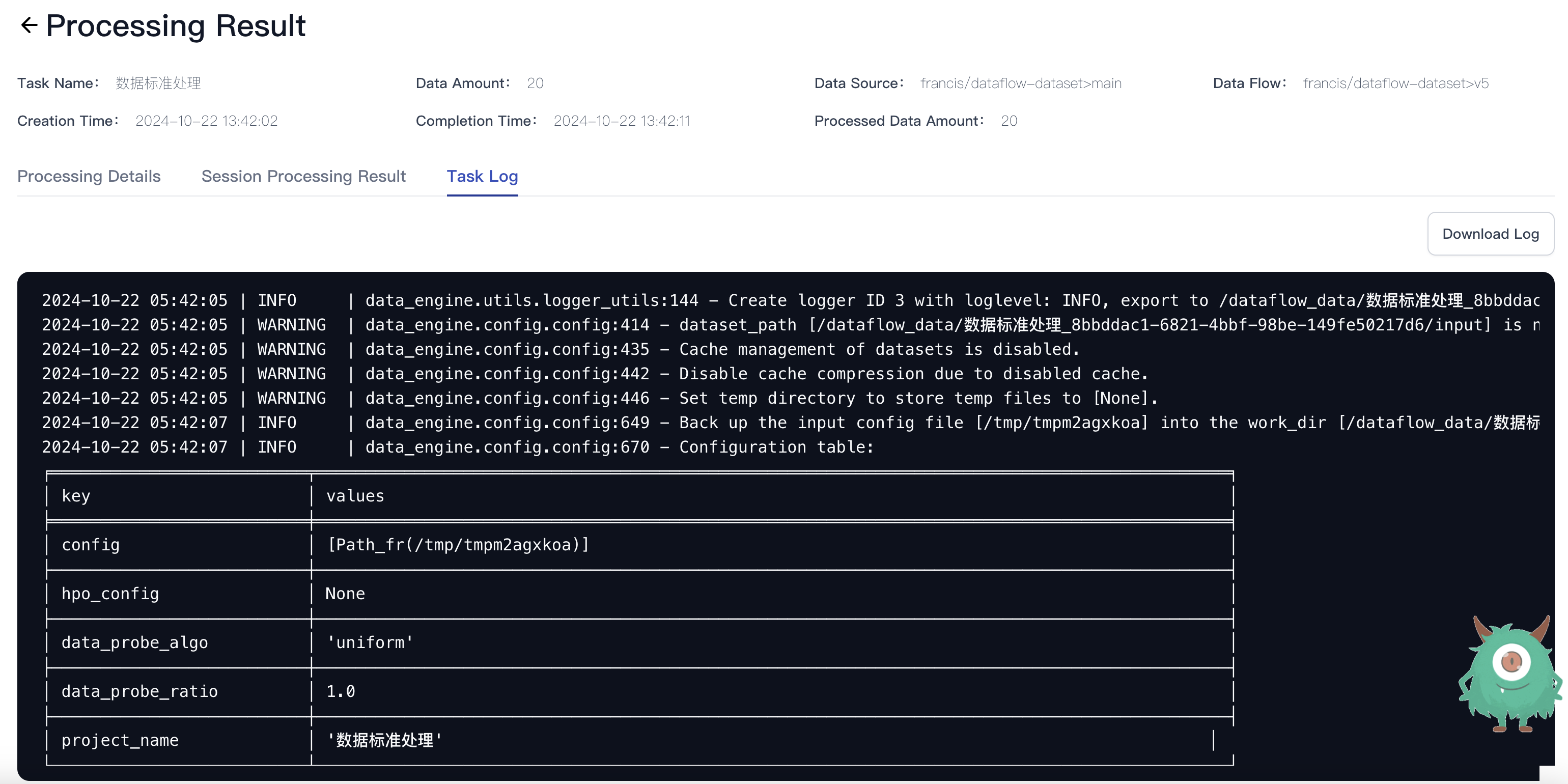
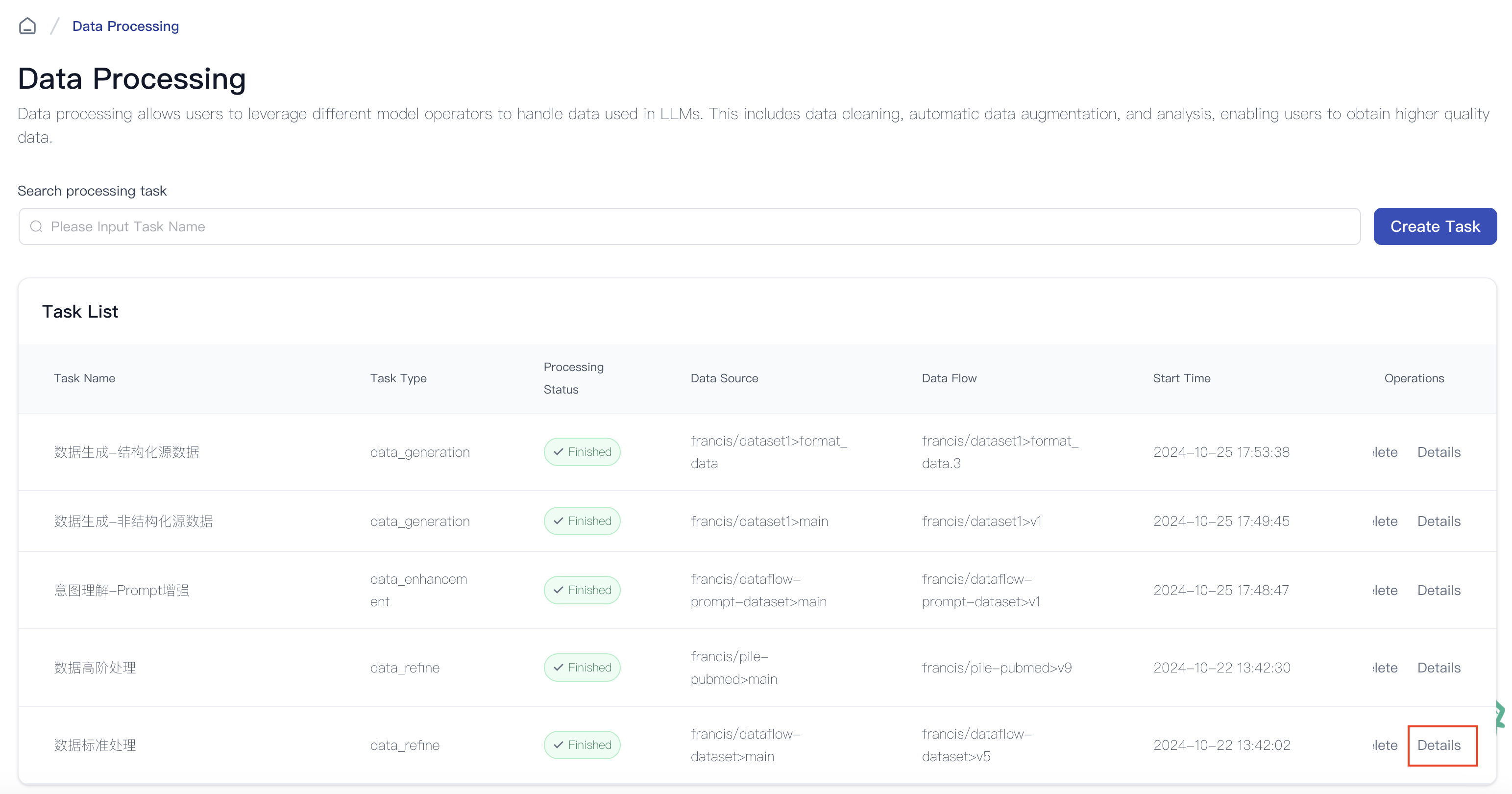
Viewing Task Details
After completion, click Details to view the task's status and results.
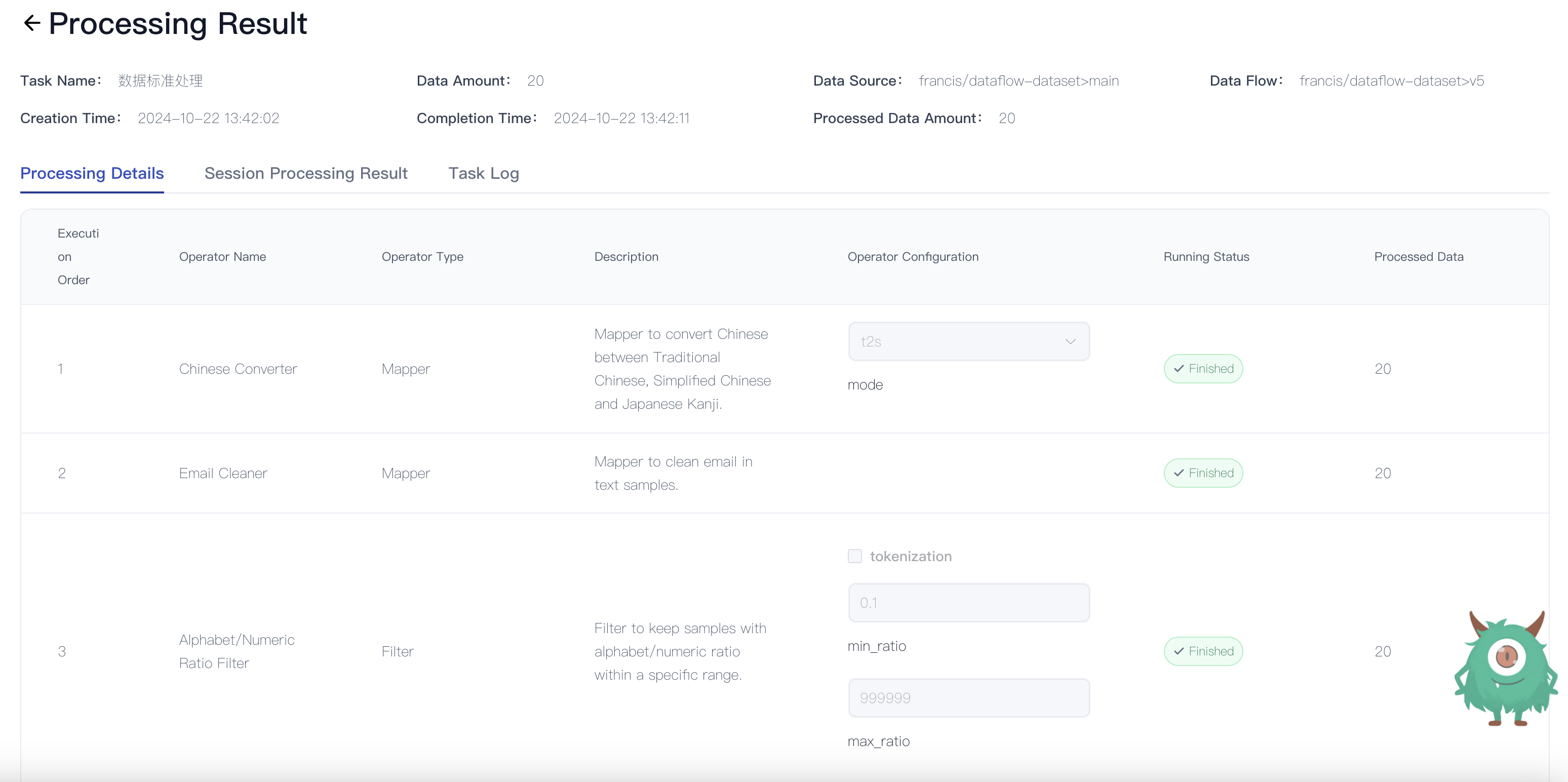
- Processing Details: Displays operator information, running status, and processed data volume for each step.
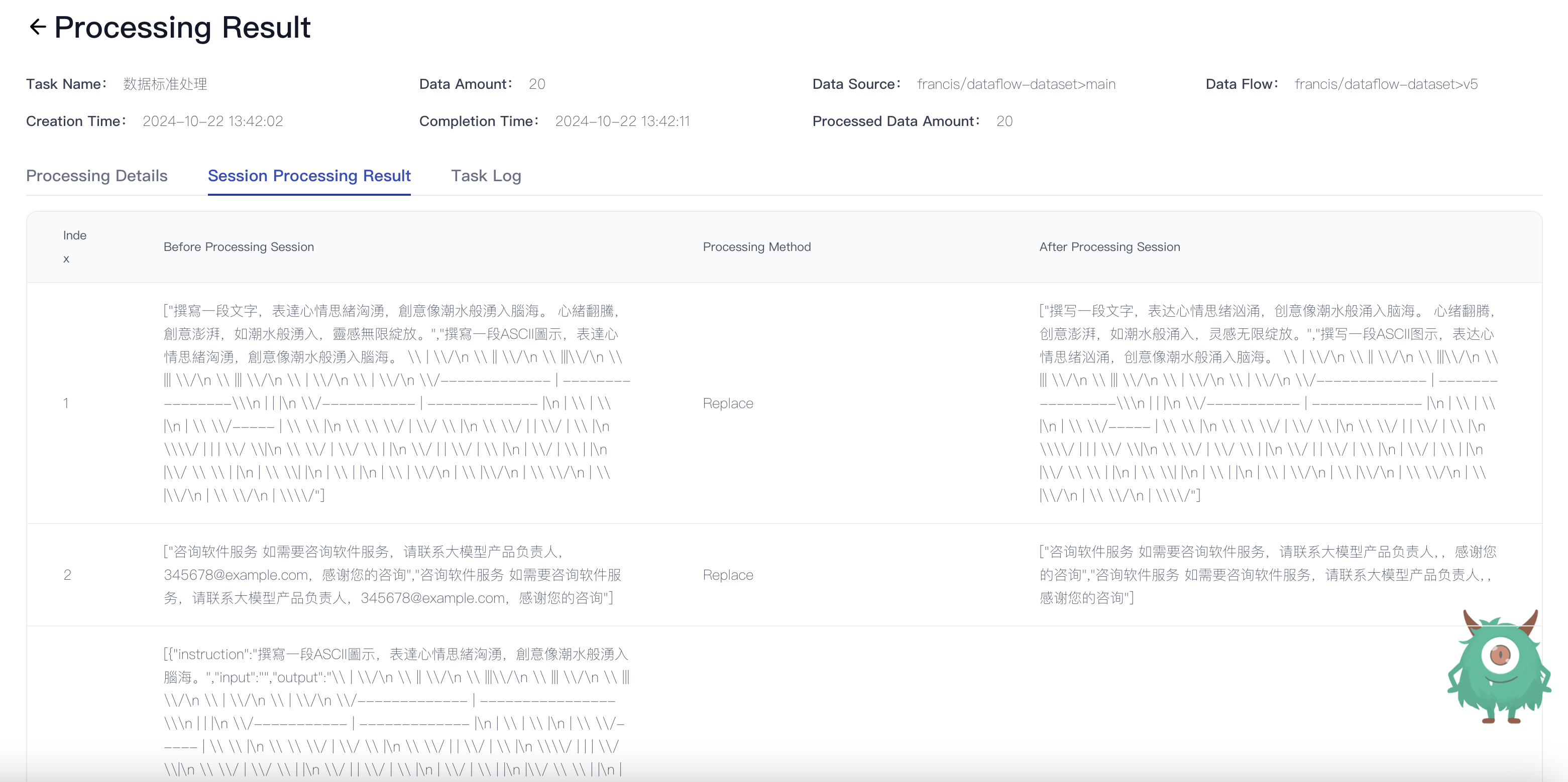
- Session Processing Result: Compare session data before and after processing to analyze performance.
- Task Log: View complete logs to track execution steps. Logs can be downloaded for further analysis.