数据处理算法模板
内置算法模板
DataFlow 内置了多种数据处理模板,包括数据处理-基础、数据处理-高阶和数据增强模板,为用户提供多样化的处理方案。未来,平台还将不断添加新的模板,以进一步丰富和优化数据处理能力。
此外,用户也可以创建自己的模板,或基于内置模板进行修改,构建个性化的数据处理 Pipeline,以满足特定的数据管理需求。
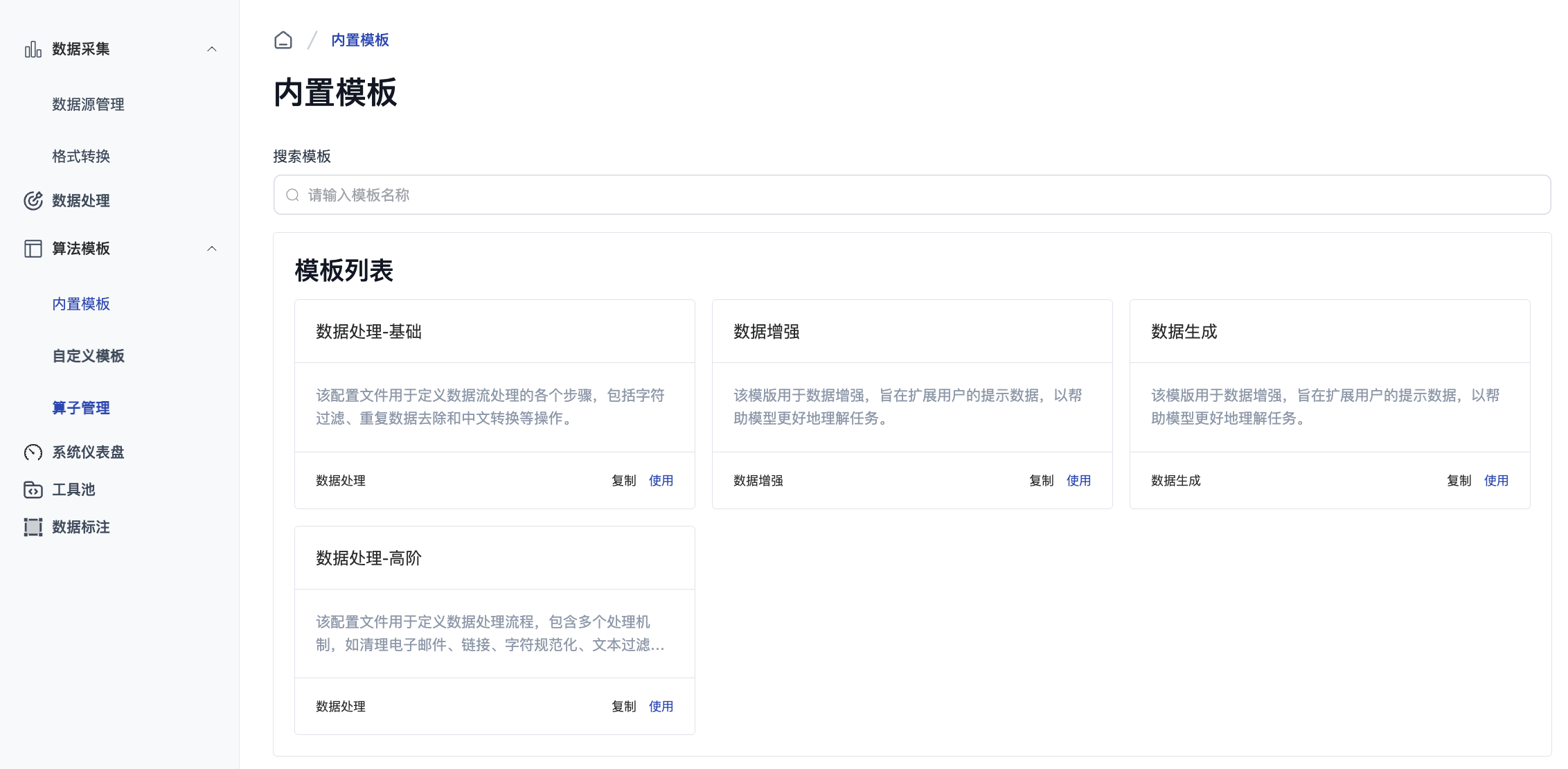
自定义算法模板
-
基于内置模板进行修改: 在内置模板卡片上点击
复制,可以复制配置,进入自定义算法模板创建页面。 -
根据需要从头创建新模板: 点击页面右侧的
自定义模板按钮,进入�自定义算法模板创建页面。

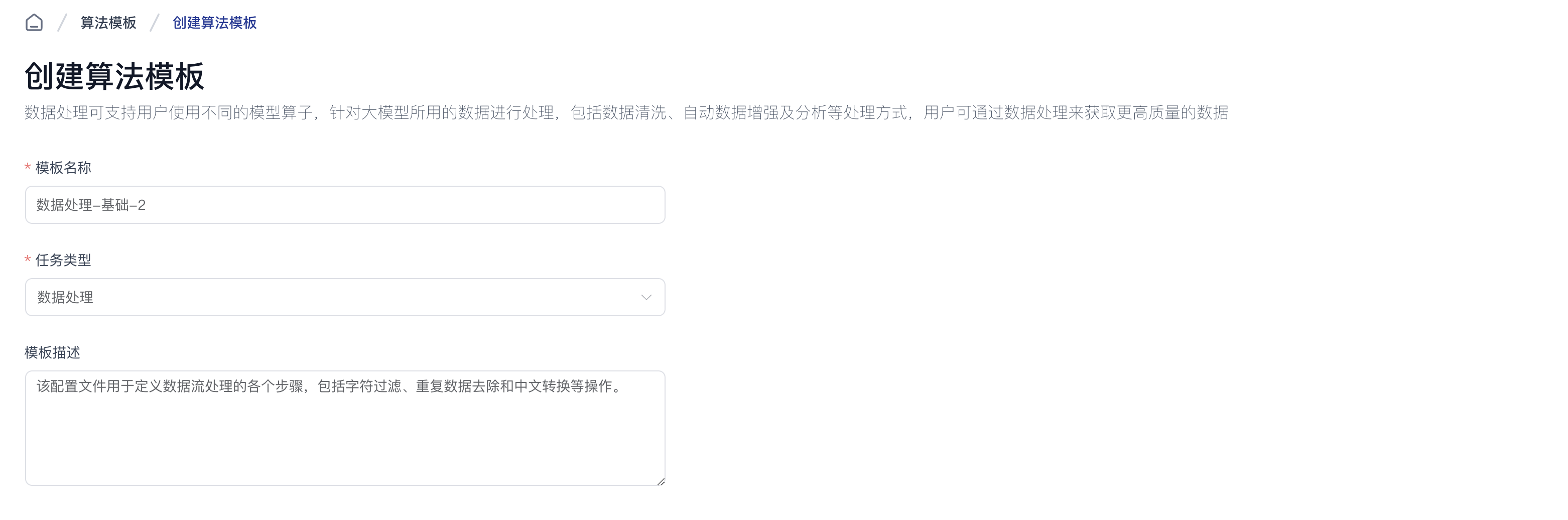
进入模板创建页面后,填写模板名称、任务类型和模板描述字段,选择模板内要使用的算子以及执行顺序。
注意:部分算子需要设置相应的参数值。
设置完成后,点击页面右下角创建完成按钮,即可开始使用新创建的模板完成数据处理任务。
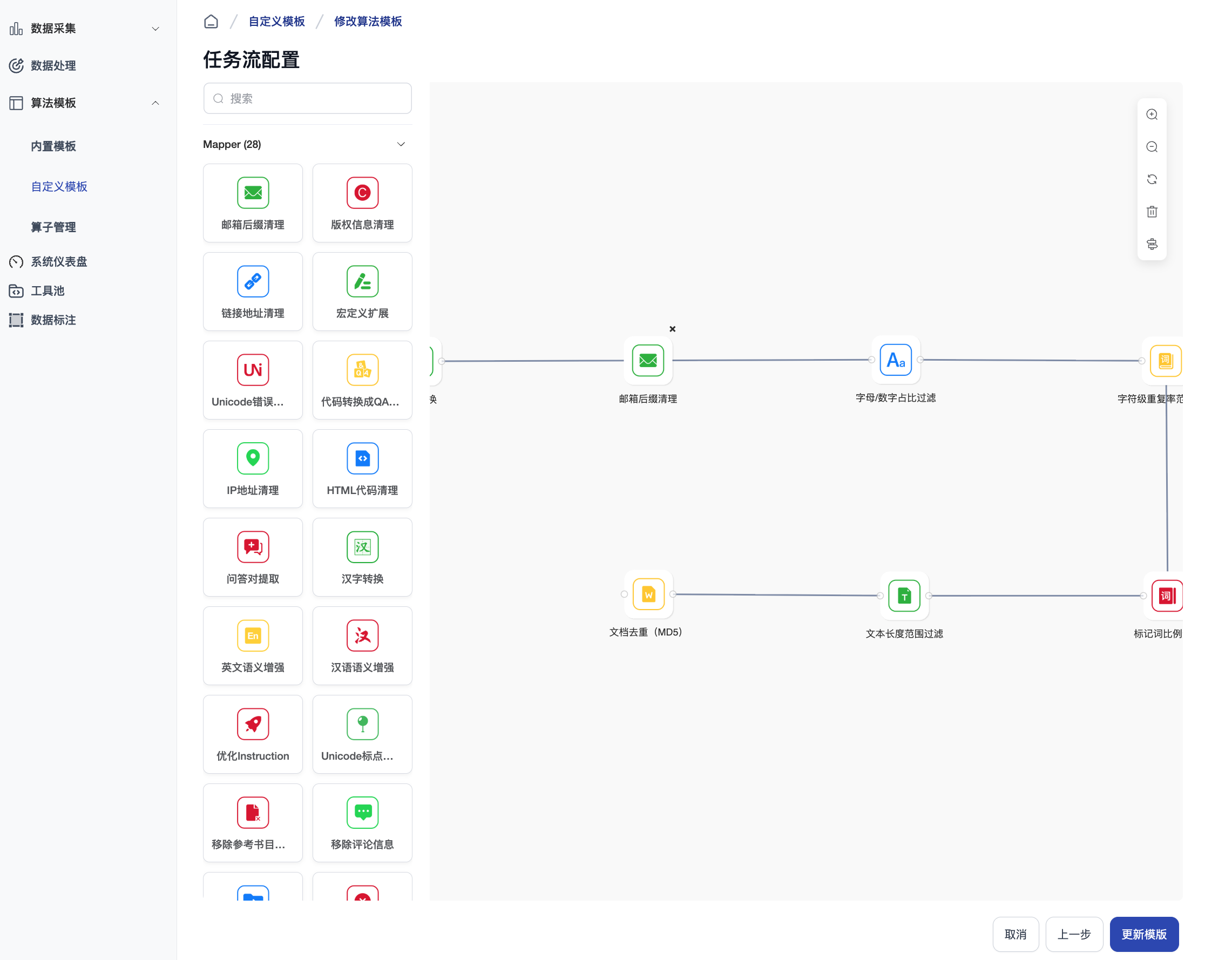
算子列表
平台支持以下算子
| ID | 名称 | 类型 | 描述 |
|---|---|---|---|
| chinese_convert_mapper | 汉字转换 | Mapper | 用于在繁体中文、简体中文和日文汉字之间进行转换。 |
| clean_copyright_mapper | 版权信息清理 | Mapper | 用于删除文本样本开头的版权声明。 |
| clean_email_mapper | 邮箱后缀清理 | Mapper | 用于删除文本样本中的电子邮件地址。 |
| clean_html_mapper | HTML代码清理 | Mapper | 用于删除文本样本中的HTML代码。 |
| clean_ip_mapper | IP地址清理 | Mapper | 用于删除文本样本中的ipv4和ipv6地址。 |
| clean_links_mapper | 链接地址清理 | Mapper | 用于删除文本样本中的http/https/ftp等链接。 |
| expand_macro_mapper | 宏定义扩展 | Mapper | 用于扩展LaTeX文档中定义的宏。 |
| generate_code_qa_pair_mapper | 代码转换成QA对数据集 | Mapper | 基于代码生成新的指令数据的转换器 |
| extract_qa_mapper | 问答对提取 | Mapper | 用于从文本样本中提取问答对 |
| fix_unicode_mapper | Unicode错误修正 | Mapper | 用于修正文本样本中Unicode错误。 |
| nlpaug_en_mapper | 英文语义增强 | Mapper | 使用nlpaug库对英语文本进行简单增强。 |
| nlpcda_zh_mapper | 汉语语义增强 | Mapper | 使用nlpcda库对中文文本进行简单增强。 |
| optimize_instruction_mapper | 优化Instruction | Mapper | 用于优化指令 |
| punctuation_normalization_mapper | Unicode标点规范化 | Mapper | 用于将文本样本中的Unicode标点符号标准化为英文标点符号。 |
| remove_bibliography_mapper | 移除参考书目信息 | Mapper | 用于删除LaTeX文档末尾的参考文献。 |
| remove_comments_mapper | 移除评论信息 | Mapper | 用于删除不同类型文档中的注释。目前仅支持'tex'格式。 |
| remove_header_mapper | 移除文件头 | Mapper | 用于移除LaTeX文档开头的标题。 |
| remove_long_words_mapper | 移除长字符串 | Mapper | 用于删除长度超出指定范围的单词。 |
| remove_non_chinese_character_mapper | 移除非中文字符 | Mapper | 用于删除文本样本中的非中文字符。 |
| remove_repeat_sentences_mapper | 句子去重 | Mapper | 用于删除文本样本中重复的句子。 |
| remove_specific_chars_mapper | 特殊字符清理 | Mapper | 用于删除文本样本中的特定字符。现在支持的字符有:◆●■►▼▲▴∆▻▷❖♡□ |
| remove_table_text_mapper | 表格内容清理 | Mapper | 用于从文本样本中删除表格内容。使用正则表达式在表格列数范围内删除表格。 |
| remove_words_with_incorrect_substrings_mapper | 子字符串清理 | Mapper | 用于删除包含错误子字符串的单词。 |
| replace_content_mapper | 文本替换 | Mapper | 用于将文本中与特定正则表达式模式匹配的所有内容替换为指定替换字符串。 |
| sentence_split_mapper | 句子分割 | Mapper | 用于将文本样本拆分为句子。 |
| whitespace_normalization_mapper | 空白规范化 | Mapper | 用于将文本样本中不同类型的空白字符标准化为空格字符' '(0x20)。 |
| alphanumeric_filter | 字母/数字占比过滤 | Filter | 用于保留字母/数字比例在特定范围内的样本。 |
| average_line_length_filter | 平均行长度范围过滤 | Filter | 用于保留平均行长度在特定范围内的样本。 |
| character_repetition_filter | 字符级重复率范围过滤 | Filter | 用于保留字符级n-gram重复率在特定范围内的样本。 |
| flagged_words_filter | 标记词比例过滤 | Filter | 用于保留标记词汇比例小于指定最大值的样本。 |
| language_id_score_filter | 特定语言置信度过滤 | Filter | 用于保留特定语言且语言置信度评分大于指定最小值的样本。 |
| maximum_line_length_filter | 最大行长度范围过滤 | Filter | 用于保留最大行长度在特定范围内的样本。 |
| perplexity_filter | 困惑度范围过滤 | Filter | 用于保留困惑度评分小于指定最大值的样本。 |
| special_characters_filter | 特殊字符比例过滤 | Filter | 用于保留特殊字符比例在特定范围内的样本。 |
| specified_field_filter | 字段信息过滤 | Filter | 基于指定字段信息进行过滤。如果样本中的指定字段信息不在设定的目标值范围内,该样本将被过滤。 |
| specified_numeric_field_filter | 数值字段范围过滤 | Filter | 基于指定的数值字段信息进行过滤。如果样本中的指定数值信息不在设定的范围内,该样本将被过滤。 |
| stopwords_filter | 停用词比例过滤 | Filter | 用于保留停用词比例大于指定最小值的样本。 |
| suffix_filter | 特殊后缀过滤 | Filter | 用于保留具有指定后缀的样本。 |
| text_action_filter | 动作文本过滤 | Filter | 用于保留包含动作的文本。 |
| text_entity_dependency_filter | 实体文本过滤 | Filter | 识别文本中独立的实体,并对其进行过滤。不包含实体的文本将被忽略。 |
| text_length_filter | 文本长度范围过滤 | Filter | 用于保留总文本长度在特定范围内的样本。 |
| token_num_filter | token数量范围过滤 | Filter | 用于保留token数量在特定范围内的样本。 |
| word_repetition_filter | 词级重复率范围过滤 | Filter | 用于保留单词级n-gram重复比率在特定范围内的样本。 |
| words_num_filter | 单词数量范围过滤 | Filter | 用于保�留总词数在特定范围内的样本。 |
| document_deduplicator | 文档去重(MD5) | Deduplicator | 用于通过精确匹配在文档级别对样本去重。使用MD5哈希值进行样本去重。 |
| document_minhash_deduplicator | 文档去重(MinHashLSH) | Deduplicator | 用于通过MinHashLSH在文档级对样本去重。与SimHash不同,MinHash以字节形式存储,因此不会保留在最终数据集中。 |
| document_simhash_deduplicator | 文档去重(SimHash) | Deduplicator | 用于在文档级别使用SimHash对样本进行去重。 |
| frequency_specified_field_selector | 排序频率选择器 | Selector | 用于根据指定字段的排序频率选择样本。 |
| random_selector | 随机样本选择器 | Selector | 用于随机对样本进行选择。 |
| range_specified_field_selector | 排序范围选择器 | Selector | 用于根据指定字段值从小到大的排序范围选择样本。 |
| topk_specified_field_selector | 前部样本的选择器 | Selector | 根据排序后的指定字段值选择前几名样本。 |
| text_high_score_filter | 打分数据筛选 | Filter | 筛选出分数大于3分的数据 |
| text_bloom_filter | 数据bloom过滤去重 | Filter | 使用 bloom 过滤器对数据集进行去重 |
| make_cosmopedia_mapper | 风格数据合成 | Mapper | 读取种子数据,将每一条种子数据作为topic,由prompt模板指定风格和体裁,然后交给 vllm 中的模型,生成指定风格的合成数据。 |
| pipeline_magpie_zh_mapper | 相似去重 | Mapper | 使用 deepseek-v2.5 或 qwen2.5 模型,根据人工设计的对应多种任务的 system_prompt,生成多轮对话数据 |
| gather_generated_data_filter | 数据聚合生成 | Filter | 聚合上一步中生成的数据,初步清洗,保存为一个文件 |
| encode_and_get_nearest_mapper | 数据样本向量编码搜索 | Mapper | 使用 gte-large-zh 模型对每条对话数据的第一个 user_query 编码为嵌入向量,并按照余弦相似度查找距离最近的样本 |
| dedup_and_save_deduplicator_deduplicator | 多轮对话生成 | Deduplicator | 根据查找结果,去重(每个相似集合只随机保留一条)。最后按任务类型保存为不同文件 |