Data Processing Tools
Tools module provides a variety of data processing tools that users can choose freely based on their needs.
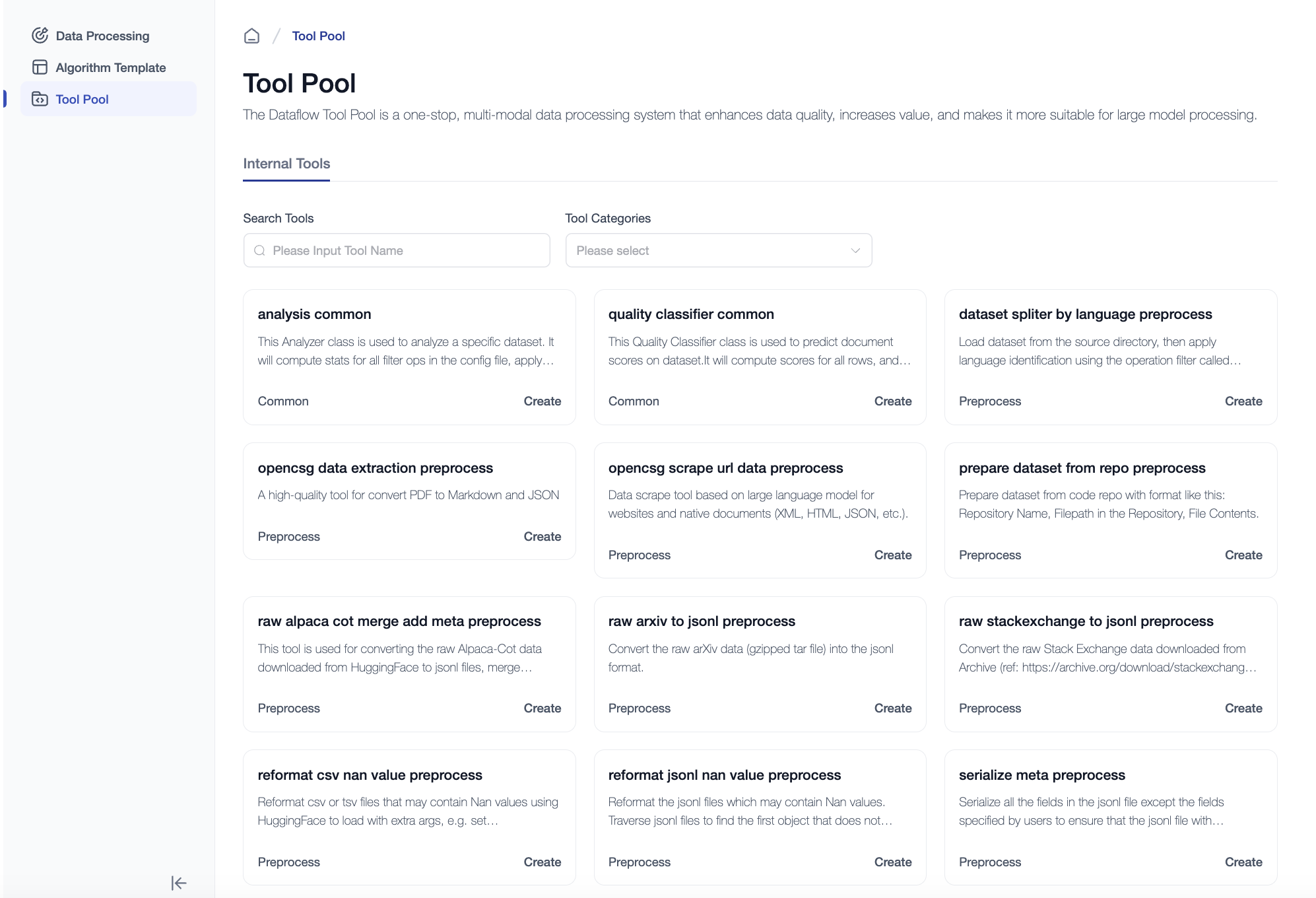
Tools List
Here is a brief description of each tool.
| Name | Description |
|---|---|
| analysis common | This Analyzer class is used to analyze a specific dataset. It will compute stats for all filter ops in the config file, apply multiple analysis (e.g. OverallAnalysis, ColumnWiseAnalysis, etc.) on these stats, and generate the analysis results (stats tables, distribution figures, etc.) to help users understand the input dataset better. |
| dataset spliter by language preprocess | Load dataset from the source directory, then apply language identification using the operation filter called LanguageIDScoreFilter, finally, split the dataset by language and save it. |
| prepare dataset from repo preprocess | prepare_dataset_from_repo_preprocess_internal_dec": "Prepare dataset from code repo with format like this: Repository Name, Filepath in the Repository, File Contents. |
| raw alpaca cot merge add meta preprocess | This tool is used for converting the raw Alpaca-Cot data to jsonl files, merge instruction/input/output to text for process, and add meta info. |
| raw arxiv to jsonl preprocess | Convert the raw arXiv data (gzipped tar file) into the jsonl format. |
| raw stackexchange to jsonl preprocess | Convert the raw Stack Exchange data downloaded from Archive (ref: https://archive.org/download/stackexchange) to several jsonl files. |
| reformat csv nan value preprocess | Reformat csv or tsv files that may contain Nan values with extra args, e.g. set keep_default_na to False. |
| reformat jsonl nan value preprocess | Reformat the jsonl files which may contain Nan values. Traverse jsonl files to find the first object that does not contain Nan as a reference feature type, then set it for loading all jsonl files. |
| serialize meta preprocess | Serialize all the fields in the jsonl file except the fields specified by users to ensure that the jsonl file with inconsistent text format for each line can also be load normally by the dataset. |
| count token postprocess | Count the number of tokens for given dataset and tokenizer. Only support 'jsonl' now. |
| data mixture postprocess | Mix multiple datasets into one dataset. Randomly select samples from every dataset and mix these samples, then export to a new mixed dataset. Supported suffixes include: ["jsonl", "json", "parquet"]. |
| deserialize meta postprocess | Deserialize the specified field in the jsonl file. |
| quality classifier common | This Quality Classifier class is used to predict document scores on dataset.It will compute scores for all rows, and give 2 columns: score and should_keep for each row to help user decide which row should be removed. By default, mark row as should_keep=1 if score is higher than 0.9. |
| opencsg scrape url data preprocess | Data scrape tool based on large language model for websites and native documents (XML, HTML, JSON, etc.). |
| data extraction & preprocessing | A high-quality tool for converting PDF files into Markdown and JSON. |
| text value assessment | Scores and filters data from the source based on user-defined criteria, and finally removes duplicates using a Bloom filter. |
| high-quality dialogue generation | Generates multi-turn dialogues using a large model with fixed prompts, and retains only the highest-quality dialogues. |
| enhanced text description tool | Uses a large model to generate detailed descriptions based on data from the source. |