Deployment of Open-Source LLMs to Build Enterprise Private Q&A Chatbots
📌 Overview
Target Users: Government agencies / State-owned enterprises / Large corporate IT departments
Products Used: CSGHub Enterprise + CSGChat On-Premises Deployment
Core Goal: Deploy open-source large language models in private enterprise networks to create internal knowledge assistants for employees, ensuring data security, high efficiency, and easy integration.
🧭 Step-by-Step Guide
Step 1: Deploy CSGHub in Your Intranet
- Install CSGHub on enterprise servers or private cloud environments using the on-premises deployment solution.
- Enable enterprise authentication and permission systems to ensure controlled internal access.
Step 2: Sync Open-Source Models
- Log in to CSGHub, navigate to [Model Hub], and use the multi-source sync feature to fetch the latest LLMs from the "Transense Open-Source Community".
- Supports models like DeepSeek, Qwen, and InternLM with version management.
- Synced models are stored locally, ensuring fully offline operation.
Step 3: Deploy Models as API Services
- Admins access the [Backend Management] module.
- Deploy selected models (e.g., Qwen-7B) as public inference services.
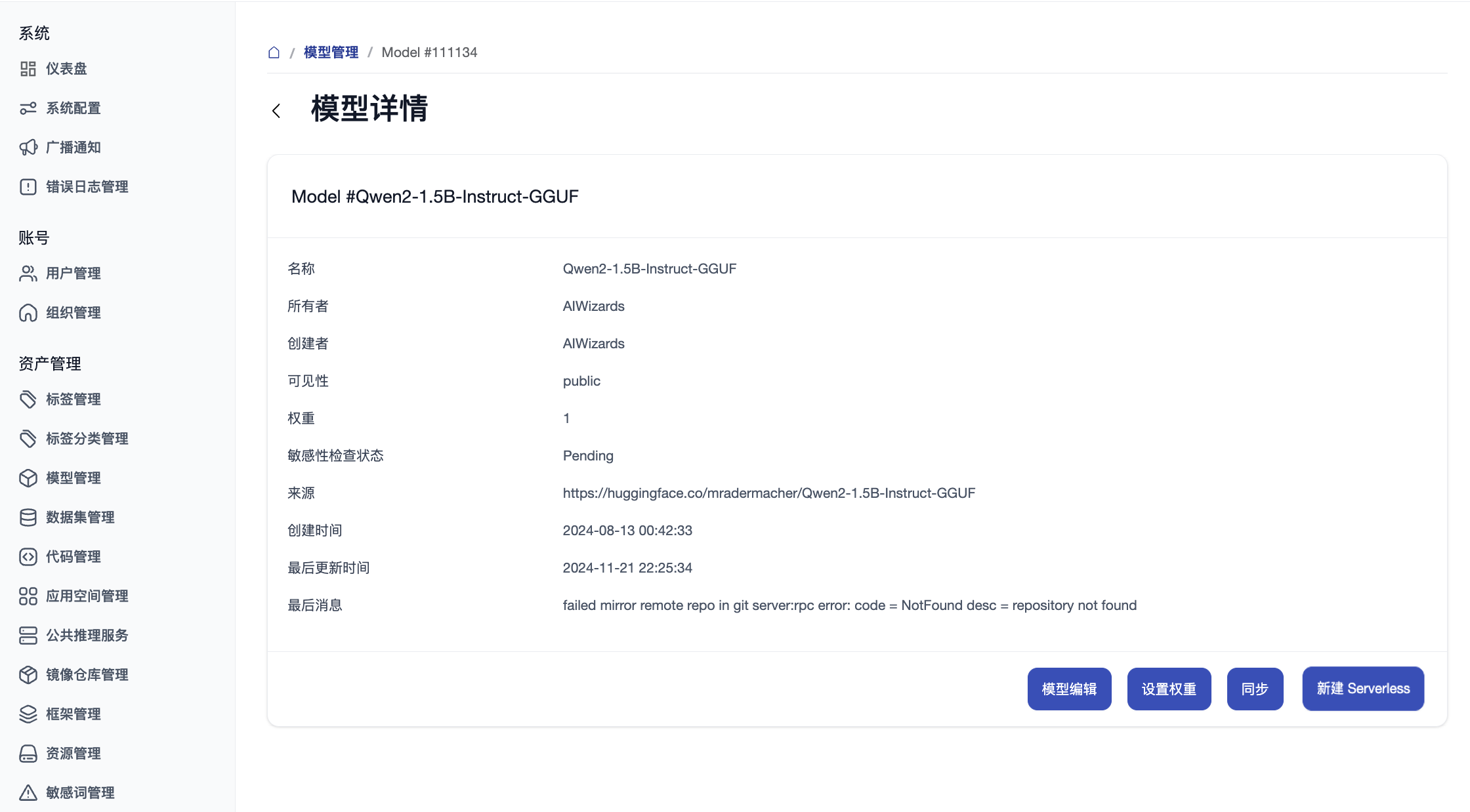
- After deployment, an "Inference API" entry appears on the model details page for direct testing.
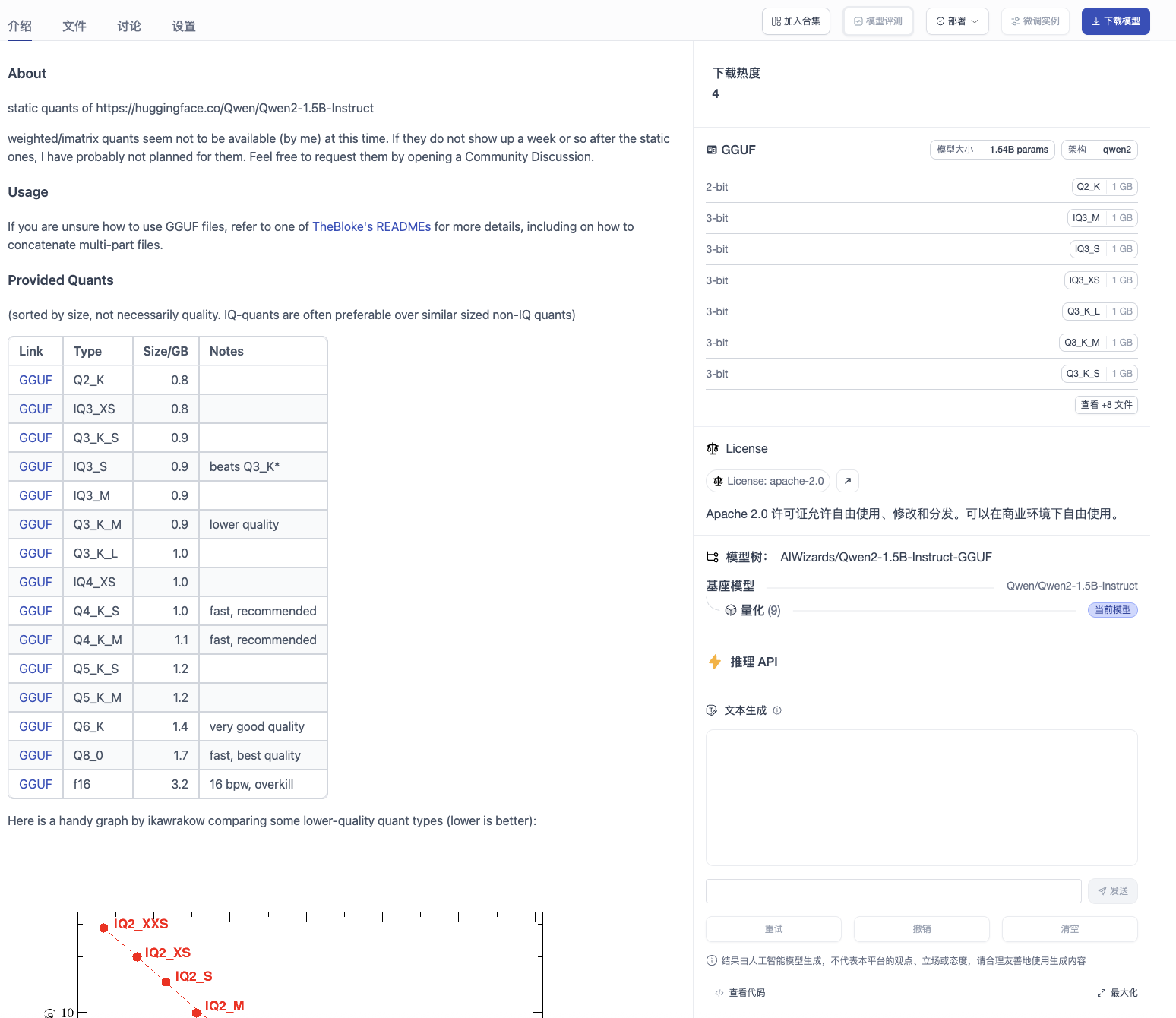
- All enterprise applications can call the model via API.
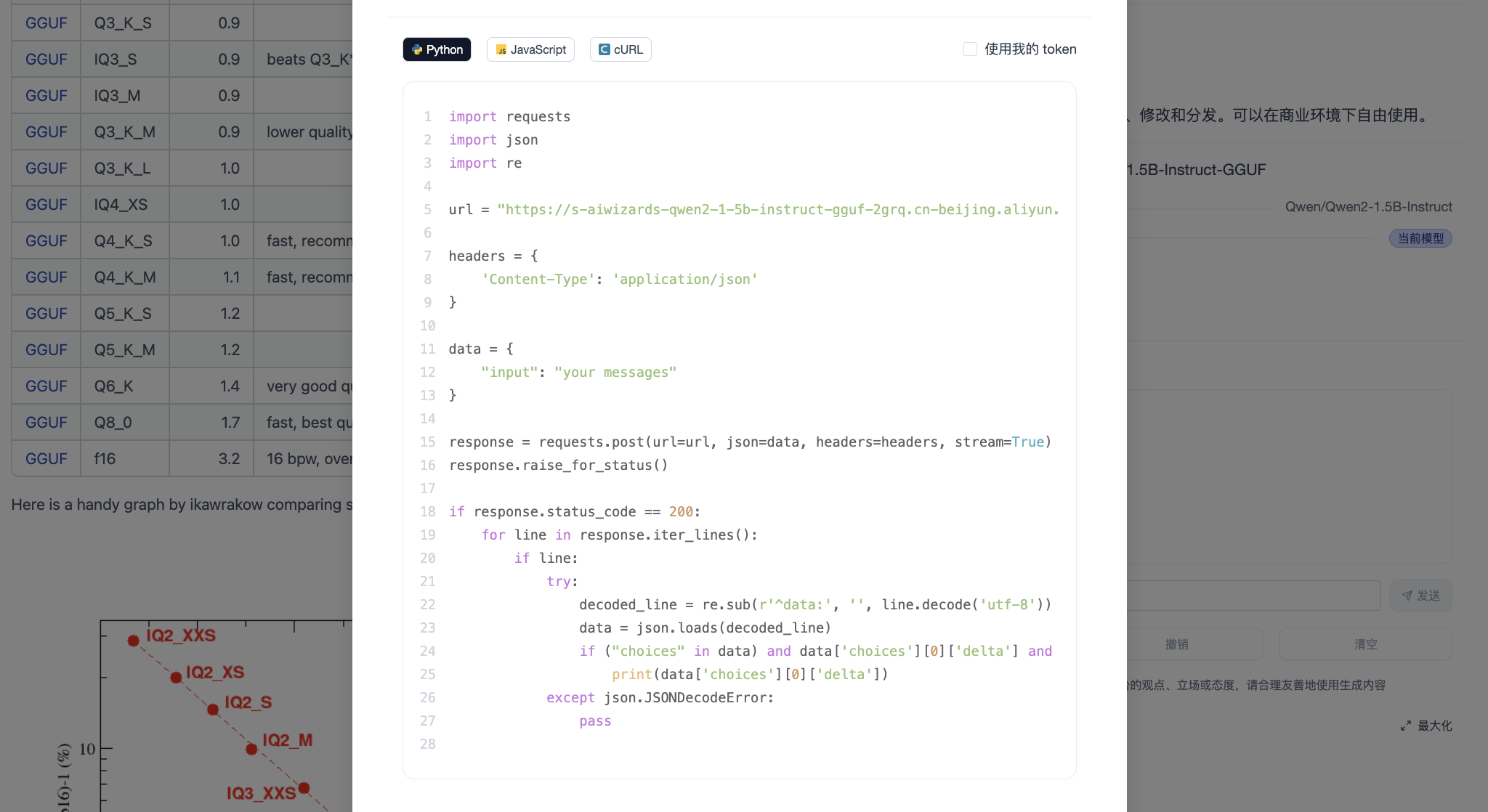
Step 4: Deploy CSGChat
- Install CSGChat, the companion component to CSGHub, and configure the model API endpoint in its backend.
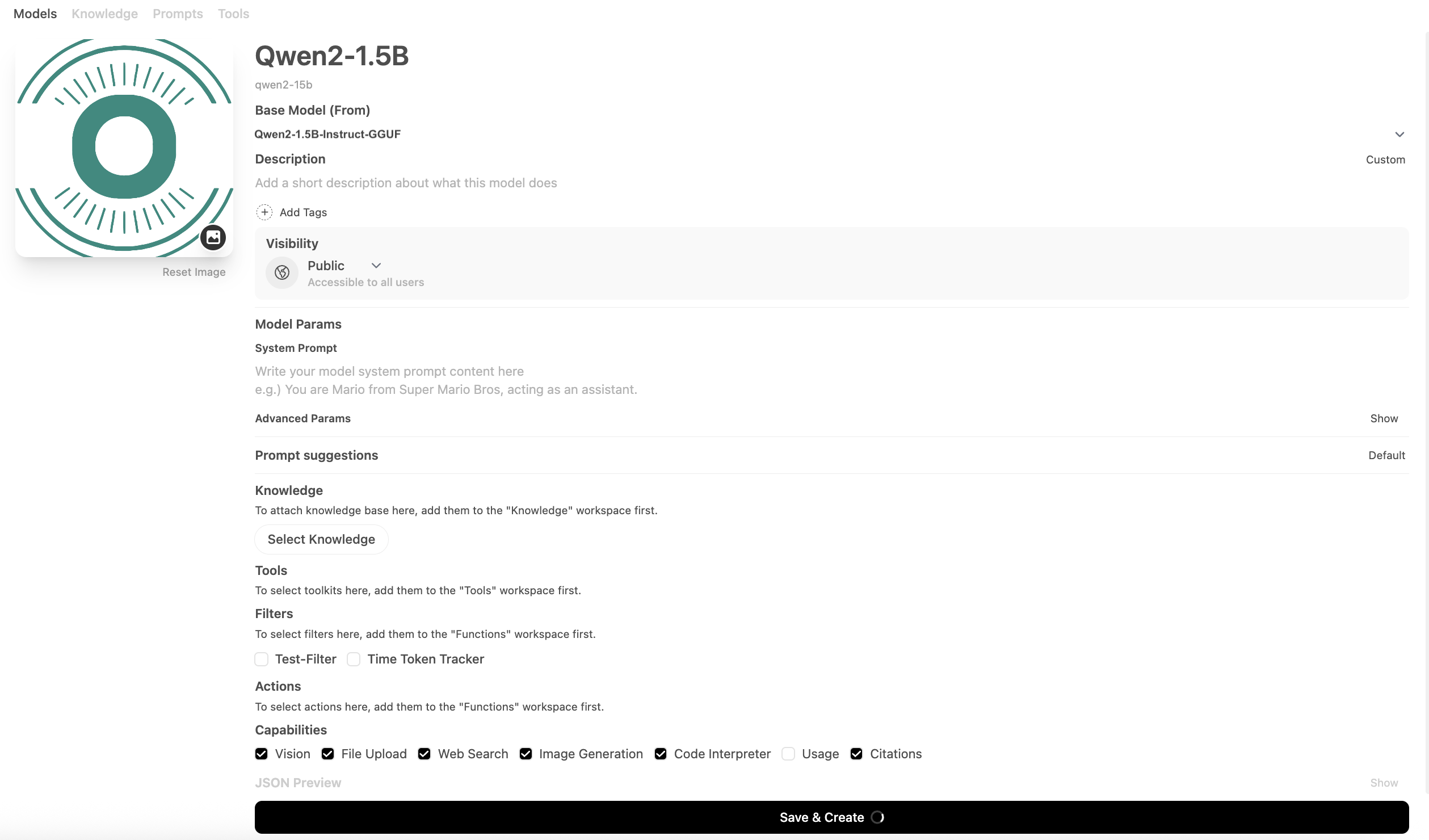
- Switch between different deployed models in CSGChat for Q&A.
Step 5: Set Up Enterprise Knowledge Base
- Upload internal documents (Word, PDF, HTML, etc.) to create a knowledge base in CSGChat.

- The system auto-generates text vectors and builds search indexes.
- Employees can ask questions in natural language and get AI-powered answers.
- Access control integrates with enterprise authentication.
🌟 Key Benefits
- Employees query policies, guidelines, and project docs via the "Smart Q&A Bot".
- Zero reliance on external LLM APIs—100% data stays in-house.
- Unified interface, consistent responses, and continuous optimization.