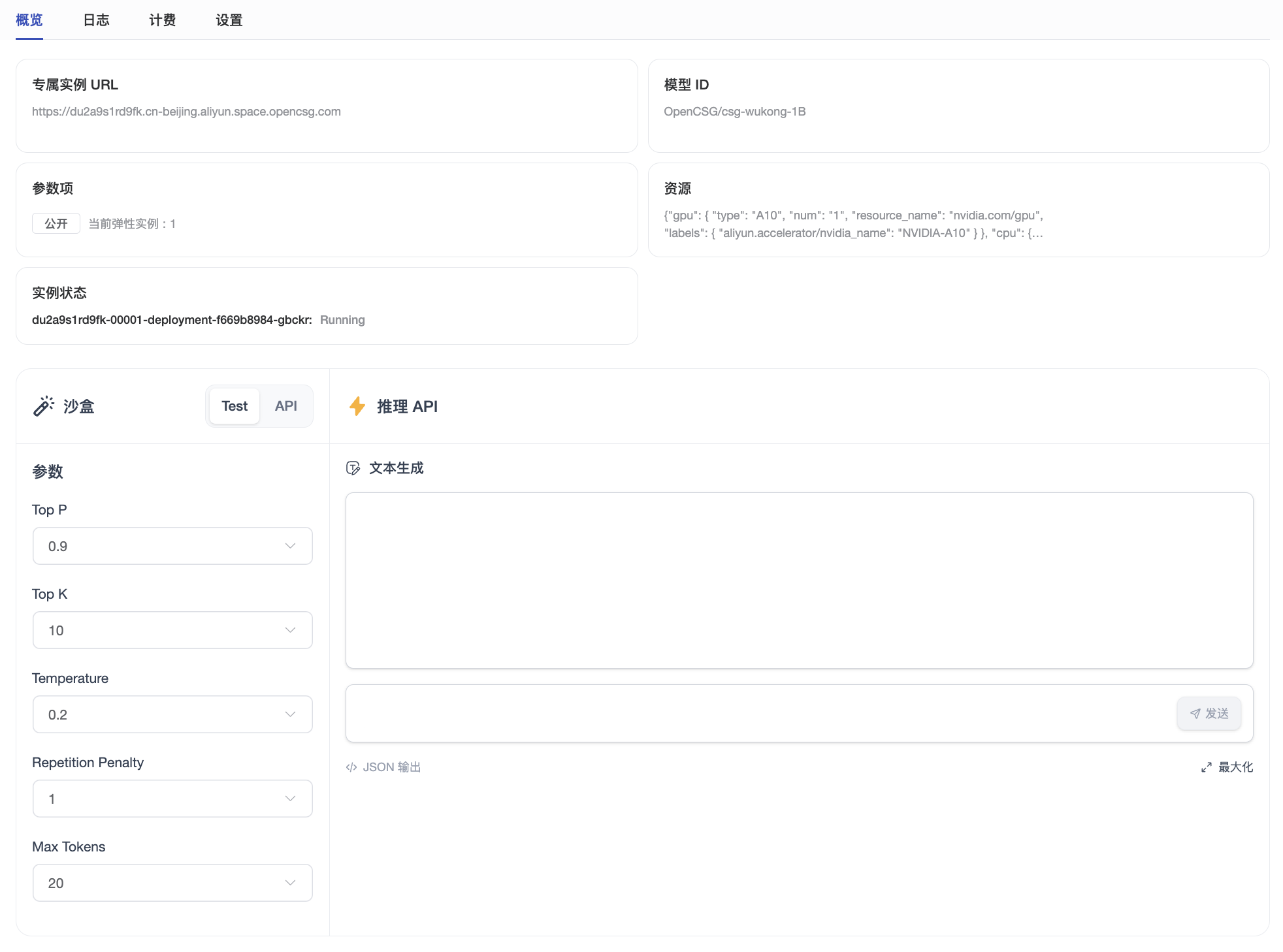
文本生成
1. 什么是文本生成任务?
文本生成(Text Generation)是大模型推理服务中的重要任务之一,旨在根据输入的文本提示(Prompt)自动生成符合上下文的连贯文本。该任务广泛应用于智能写作、对话系统、代码生成、摘要提取等多个场景。
2. 典型应用场景
- 内容创作:生成文章、故事、诗歌、广告文案等。
- 对话系统:用于智能客服、聊天机器人,提供自然流畅的对话能力。
- 代码生成:根据需求描述自动生成代码,提高开发效率。
- 文本摘要:对长篇文档进行摘要,提炼核心信息。
- 机器翻译:将文本从一种语言自动翻译为另一种语言。
3. 影响推理效果的关键因素
模型选择
不同模型在文本流畅度、信息准确性等方面表现不同,应根据具体任务需求选择合适的模型。
参数调整
以下是影响文本生成效果的重要参数:
温度(Temperature)
- 控制生成文本的创造力。
- 温度高(如
1.0):生成的内容更丰富、变化更多,但可能不够严谨。 - 温度低(如
0.1):文本更加稳定和可预测,但可能较为单调。
- 温度高(如
- 应用场景:适用于控制文本的自由度。
最大长度(Max Length)
- 限制生成文本的字数,避免生成内容过长或过短。
Top-K 采样
-
限制模型在生成时只考虑最有可能的
K个词。 例如,K=50时,模型只会在最相关的 50 个词中选择,有助于提高生成质量,减少随机性。 -
应用场景:
-
当您希望生成更正式、更严谨的文本时,可以使用较�小的
top_k值。 -
当您希望生成更具创意、更具多样性的文本时,可以使用较大的
top_k值。 -
top_k设置为0(或者不设置),代表不启用top_k采样。
Top-P 采样
- 根据概率动态选择词汇,而不是固定数量。例如,仅考虑总概率达到
90%的单词范围,更加灵活。 - 应用场景:
- 当您希望在生成结果的随机性和多样性之间取得平衡时,可以使用
top_p参数。 top_p设置为1(或者不设置),代表不启用top_p采样。
重复惩罚(Repetition Penalty)
- 控制模型对重复短语的偏好,较高的惩罚可以减少冗余内容。
- 应用场景:避免生成内容时重复同样的词或句子.
4. 代码调用示例
import requests
url = "https://xxxxxxxxxxxx.space.opencsg.com/v1/chat/completions" #endpoint url
headers = {
'Content-Type': 'application/json'
}
data = {
"model": "xzgan001/Qwen2-1.5B-Instruct-GGUF",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "What is deep learning?"
}
],
"stream": True,
"temperature": 0.2,
"max_tokens": 200,
"top_k": 10,
"top_p": 0.9,
"repetition_penalty": 1
}
response = requests.post(url=url, json=data, headers=headers, stream=True)