How to Fine-Tune a Model Using LLaMA Factory
LLaMA Factory is an efficient model fine-tuning framework that helps users quickly fine-tune large language models (LLMs). This guide will introduce how to prepare datasets and use the LLaMA Factory Web UI to configure the essential training parameters for fine-tuning your first model.
Dataset Preparation
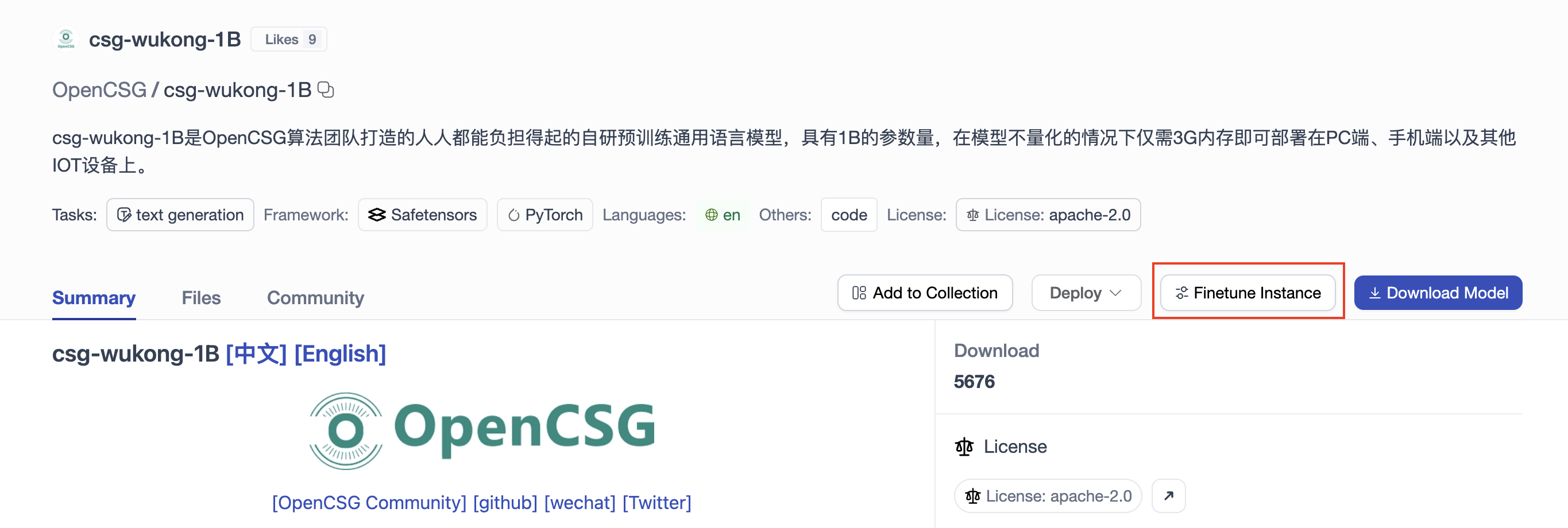
First, we can find a model supported by LLaMA Factory from the OpenCSG community. In this tutorial, we will fine-tune the pre-trained model "csg-wukong-1B" developed by the OpenCSG algorithm team using the LLaMA Factory framework.
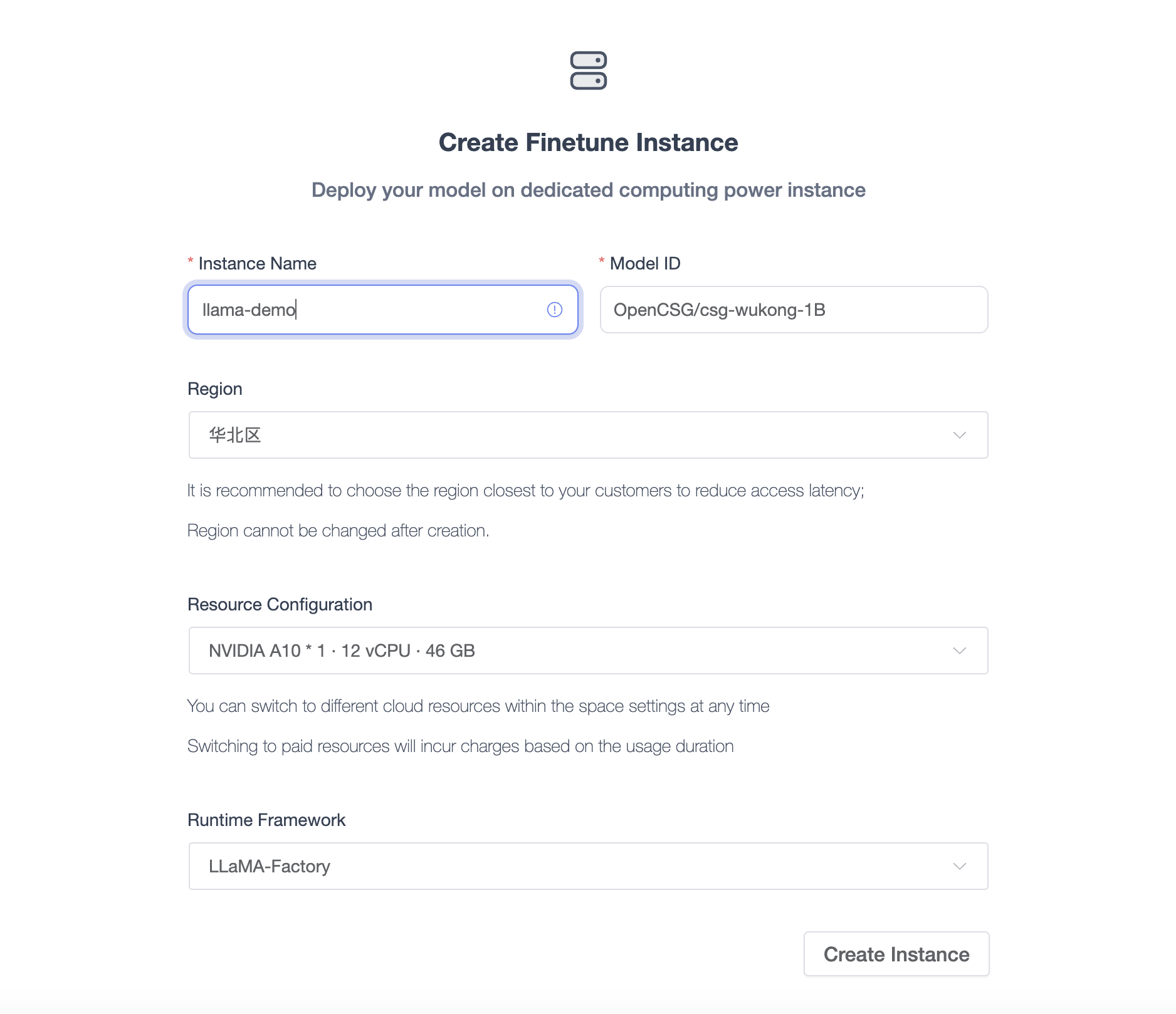
Go to the model page and click Fine-Tune Instance to navigate to the creation page. After creating and starting the instance, you can begin fine-tuning the model.
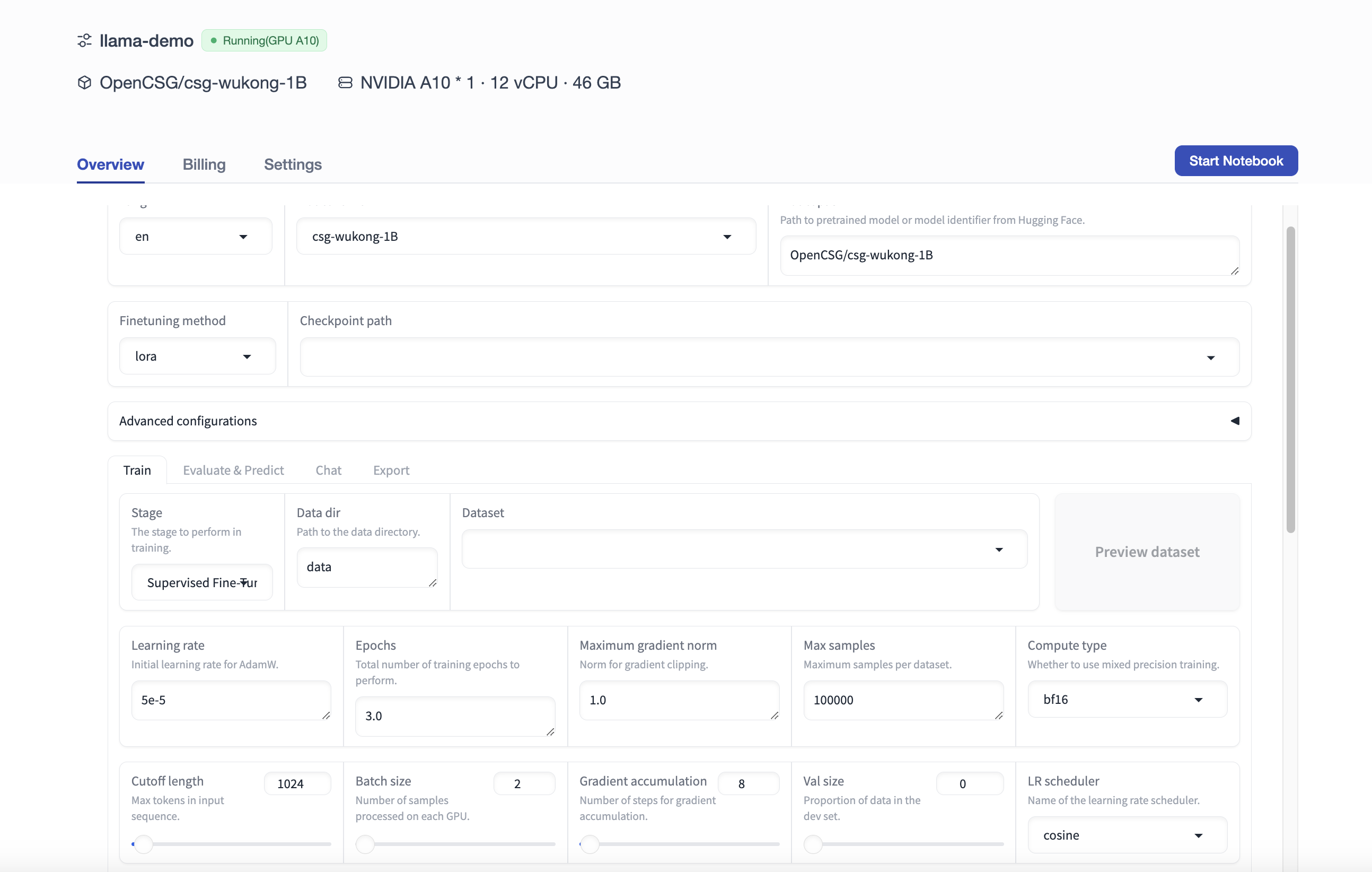
LLaMA Factory comes with some default datasets stored in the data directory. You can either use these built-in datasets or upload your own private dataset in the required format for the framework, place it in the data directory, and add descriptions and definitions of the dataset in the dataset_info.json file.
Currently, datasets in Alpaca format and ShareGPT format are supported. You can find the specific requirements for different dataset formats in the official LLaMA Factory documentation:
Note: If you are using a custom dataset, ensure that the description of the dataset is added to the
data/dataset_info.jsonfile and that the dataset format is accurate, otherwise, it may lead to training failure.
If you want to directly use a dataset from CSGHUB, you can follow the same style as the fine-tune export setup: set hf_hub_url in dataset_info.json to the CSGHUB dataset path. For example:
"alpaca_gpt4_en": {
"hf_hub_url": "James/alpaca_gpt4_en",
"ms_hub_url": "llamafactory/alpaca_gpt4_en"
},
Model Fine-Tuning
Web UI Overview
LLaMA Factory provides an intuitive Web UI where users can fine-tune models, adjust parameters, and monitor training progress easily.
The Web UI is divided into four main sections: Train, Evaluate & Predict, Chat, and Export.
Parameter Configuration
In the Web UI, you can easily adjust various parameters through the interface. Below are some key parameters and adjustment suggestions. Parameters not mentioned in this tutorial should be left at their default values. You can adjust them according to your actual business needs.
-
Lang:
- By default, the Web UI uses English (en). You can switch to Chinese (zh).
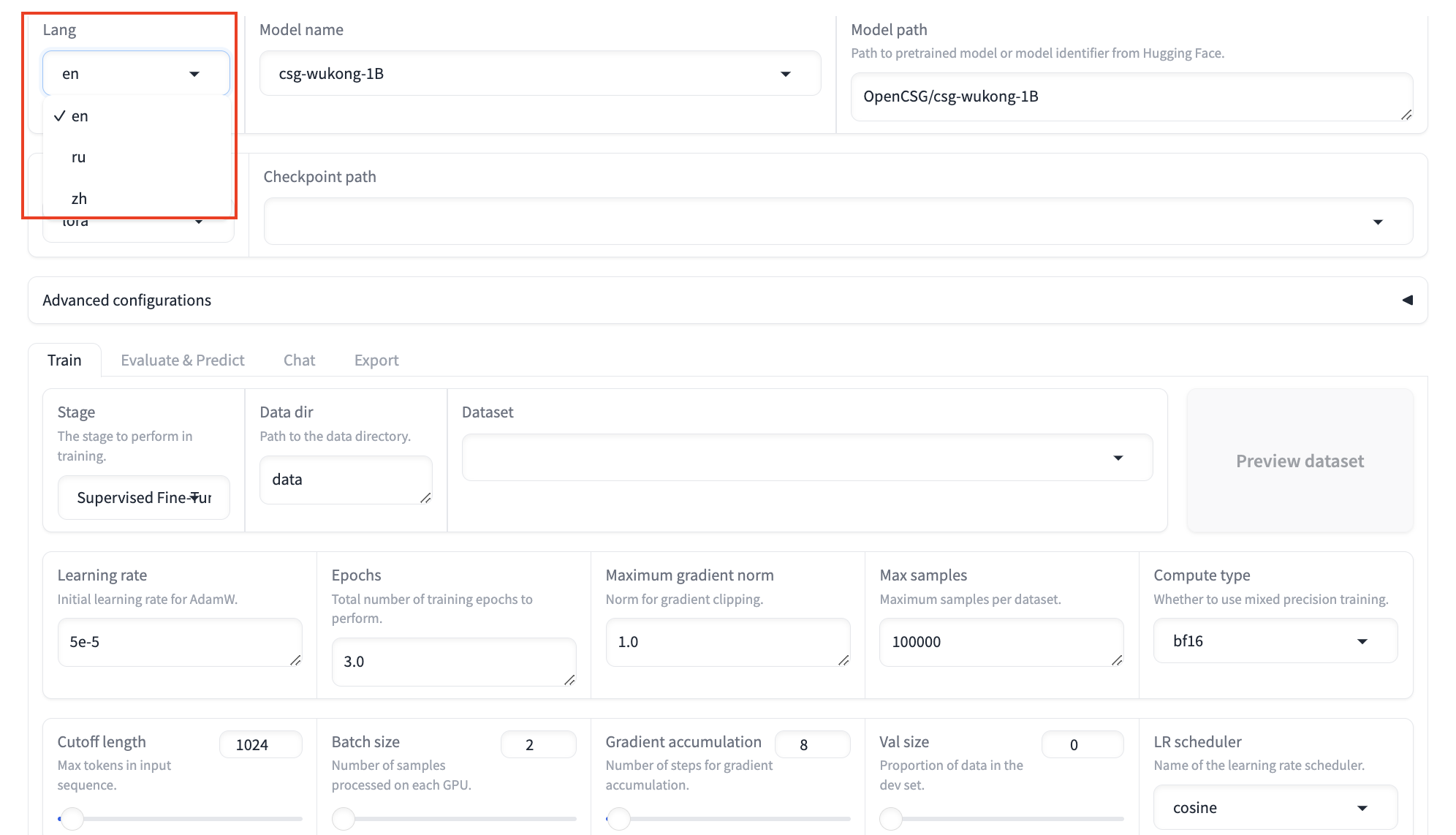
- By default, the Web UI uses English (en). You can switch to Chinese (zh).
-
Model Name:
- By default, the Web UI will load the model you provide. In this tutorial, we are using
csg-wukong-1B. - If you want to use a different model, you can select it in the interface.
- By default, the Web UI will load the model you provide. In this tutorial, we are using
-
Finetuning Method:
- There are three fine-tuning methods. By default, the lora method is used. The LoRA lightweight fine-tuning method greatly reduces memory usage.
- full: Fine-tune the entire model, which requires significant memory.
- freeze: Freeze most of the model parameters and only fine-tune a part of them to reduce memory requirements.
- lora: Freeze part of the model parameters and fine-tune only specific layers to significantly save memory.
- If you want to use one of the other two fine-tuning methods, you can select them in the interface.
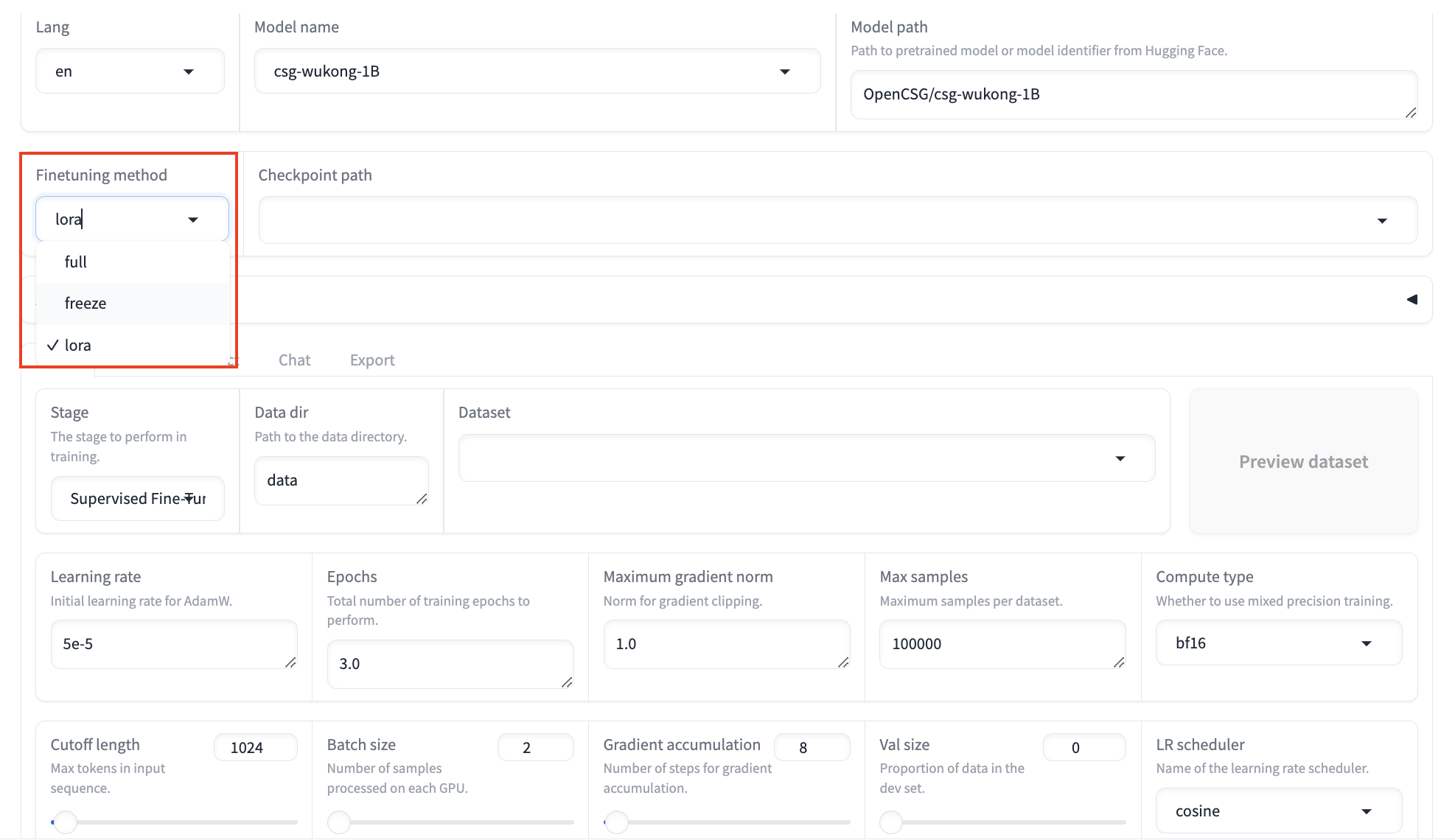
- There are three fine-tuning methods. By default, the lora method is used. The LoRA lightweight fine-tuning method greatly reduces memory usage.
-
Dataset:
- In this tutorial, we use the built-in dataset
alpaca_zh_demo, but you can also use your private dataset. After selecting the dataset, you can click Preview Dataset to view details. Click Close to return to the fine-tuning interface.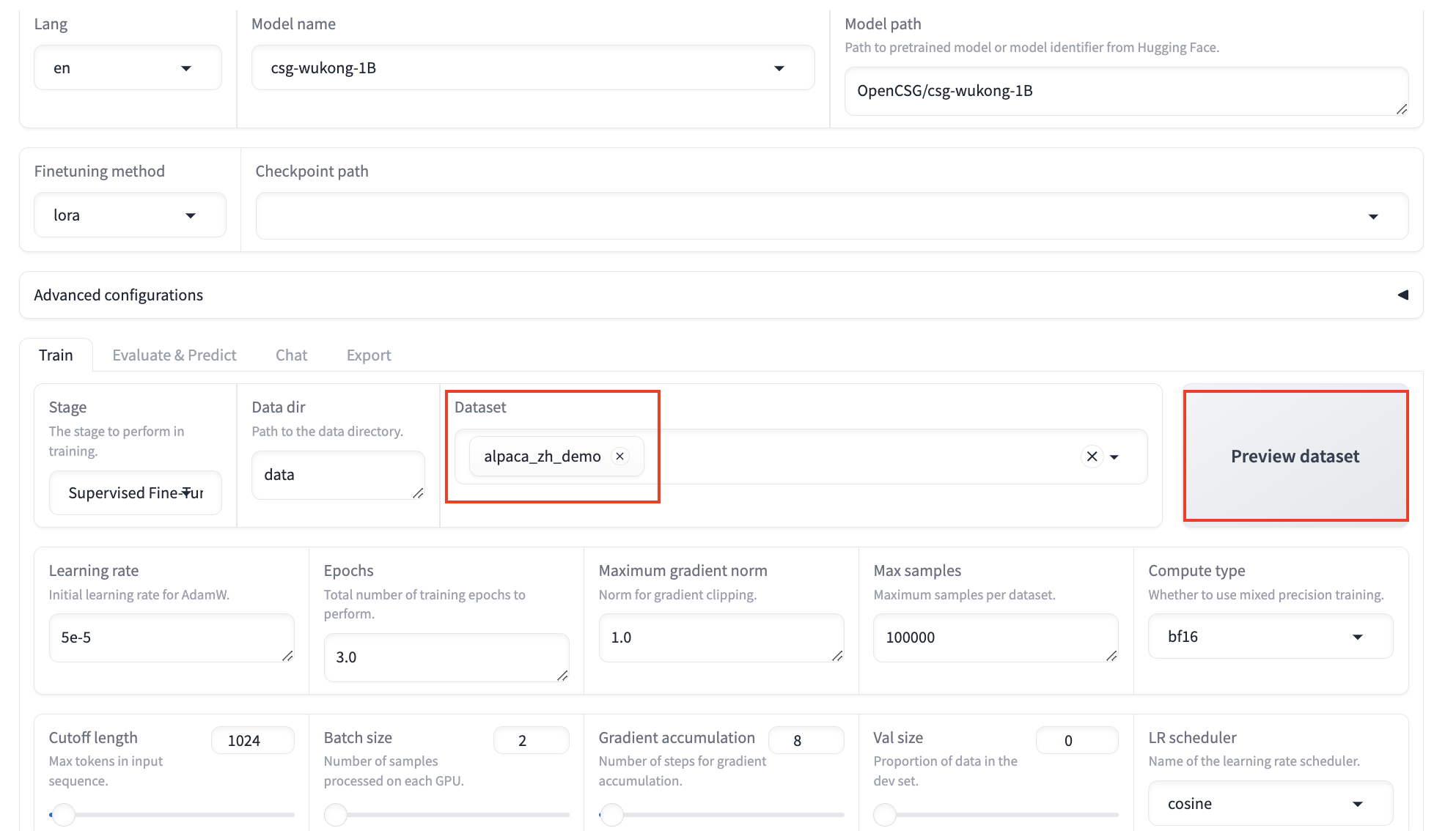
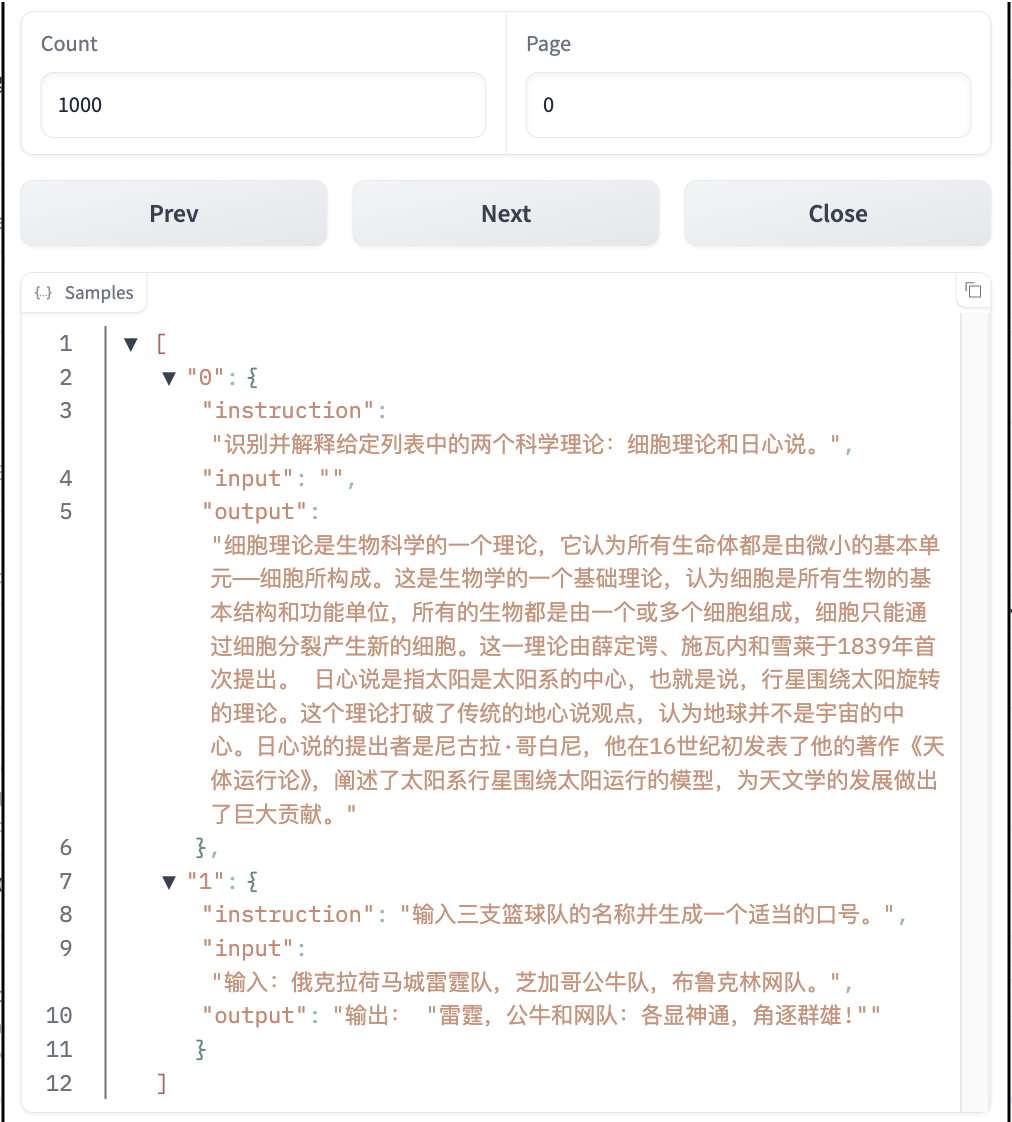
- In this tutorial, we use the built-in dataset
-
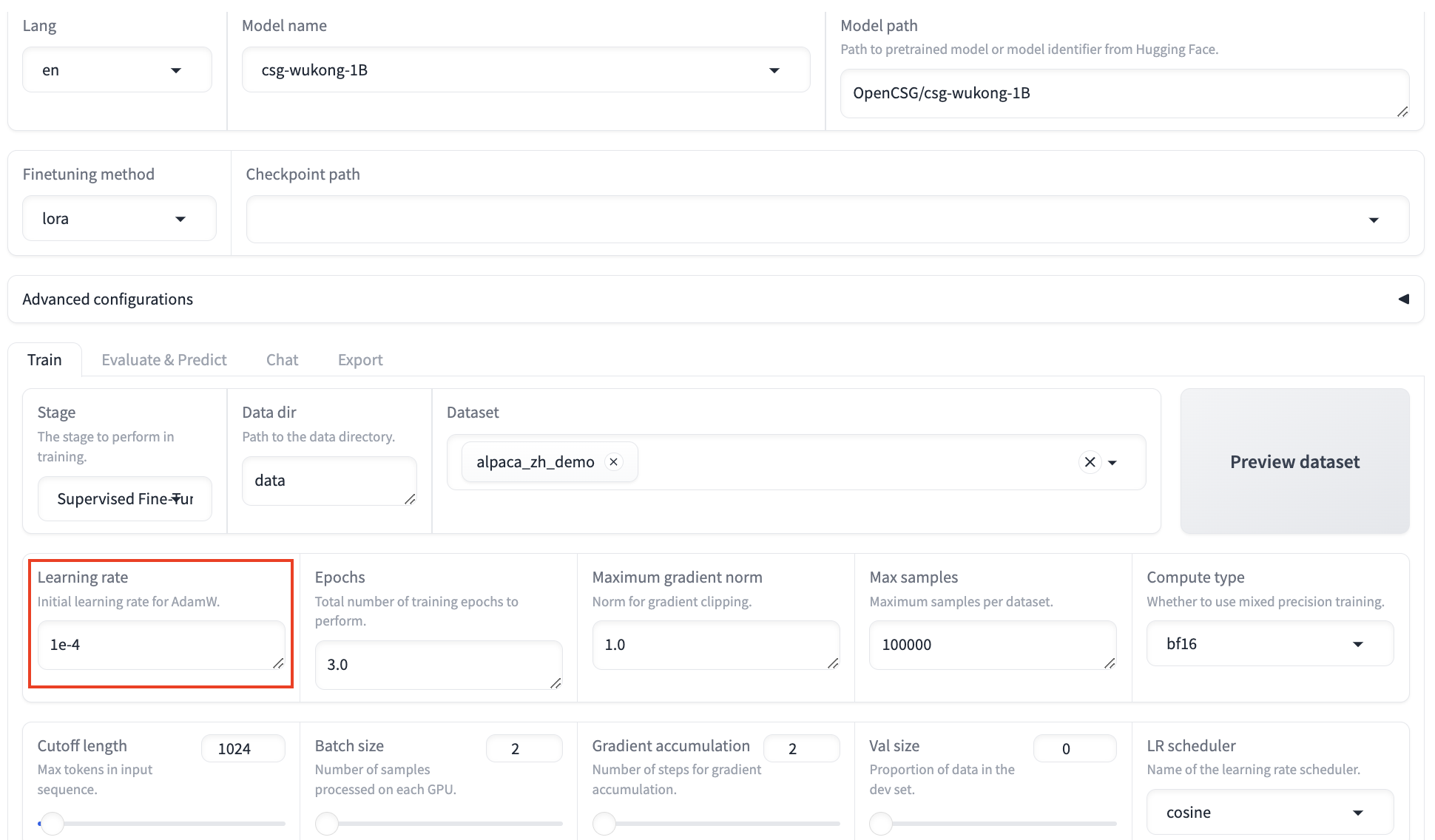
Learning Rate:
- The learning rate determines how quickly the model updates during training. A high learning rate may cause the model to learn too quickly and become unstable, while a low learning rate may cause slow learning and reduce efficiency. Adjust the learning rate based on the dataset size and task complexity.
- In this tutorial, the learning rate is set to 1e-4, which helps model convergence.
-
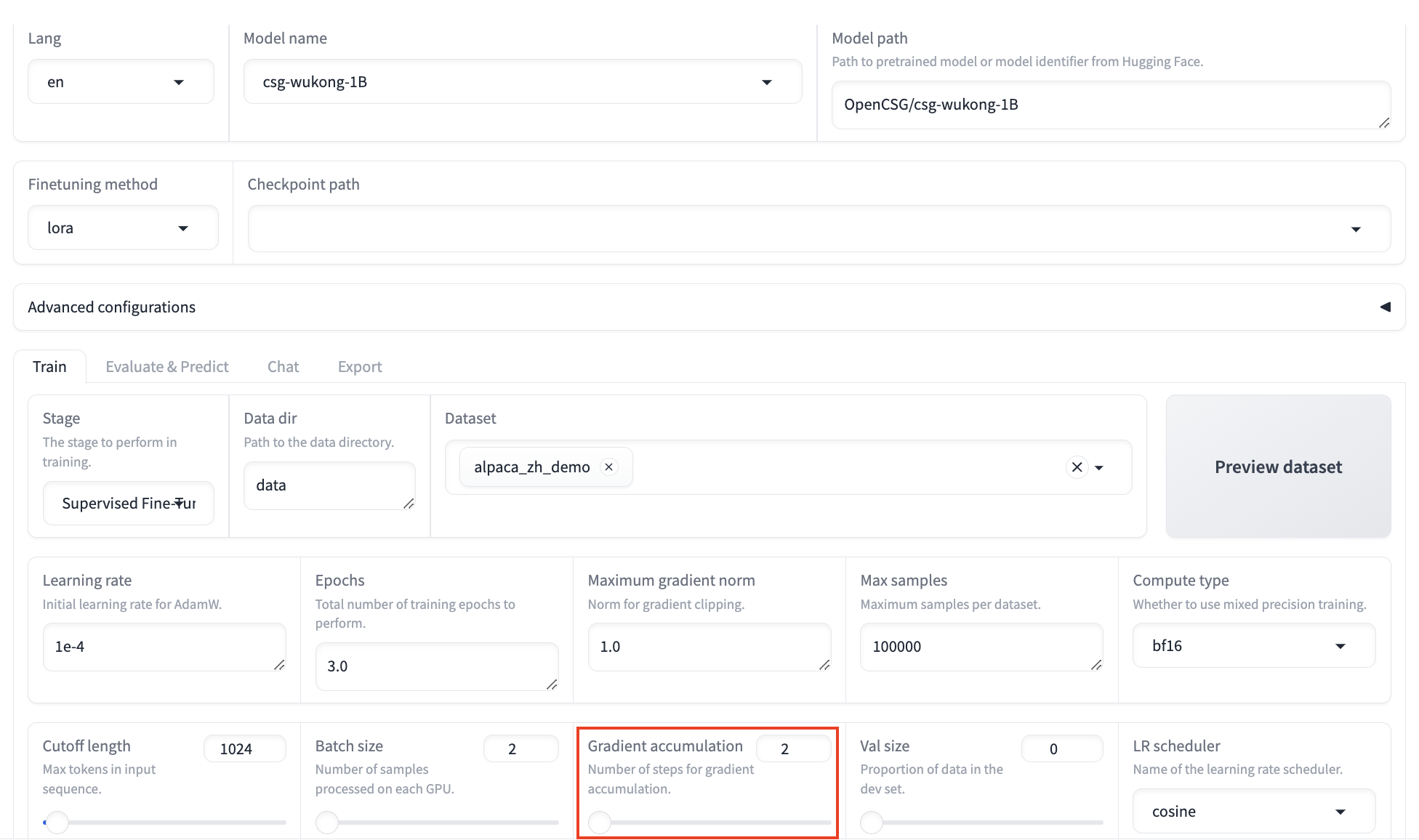
Gradient Accumulation:
- Gradient accumulation helps simulate large batch training with smaller batches. For environments with limited memory, increasing the accumulation steps ensures the training effectiveness.
- In this tutorial, gradient accumulation is set to 2, which helps model convergence.
-
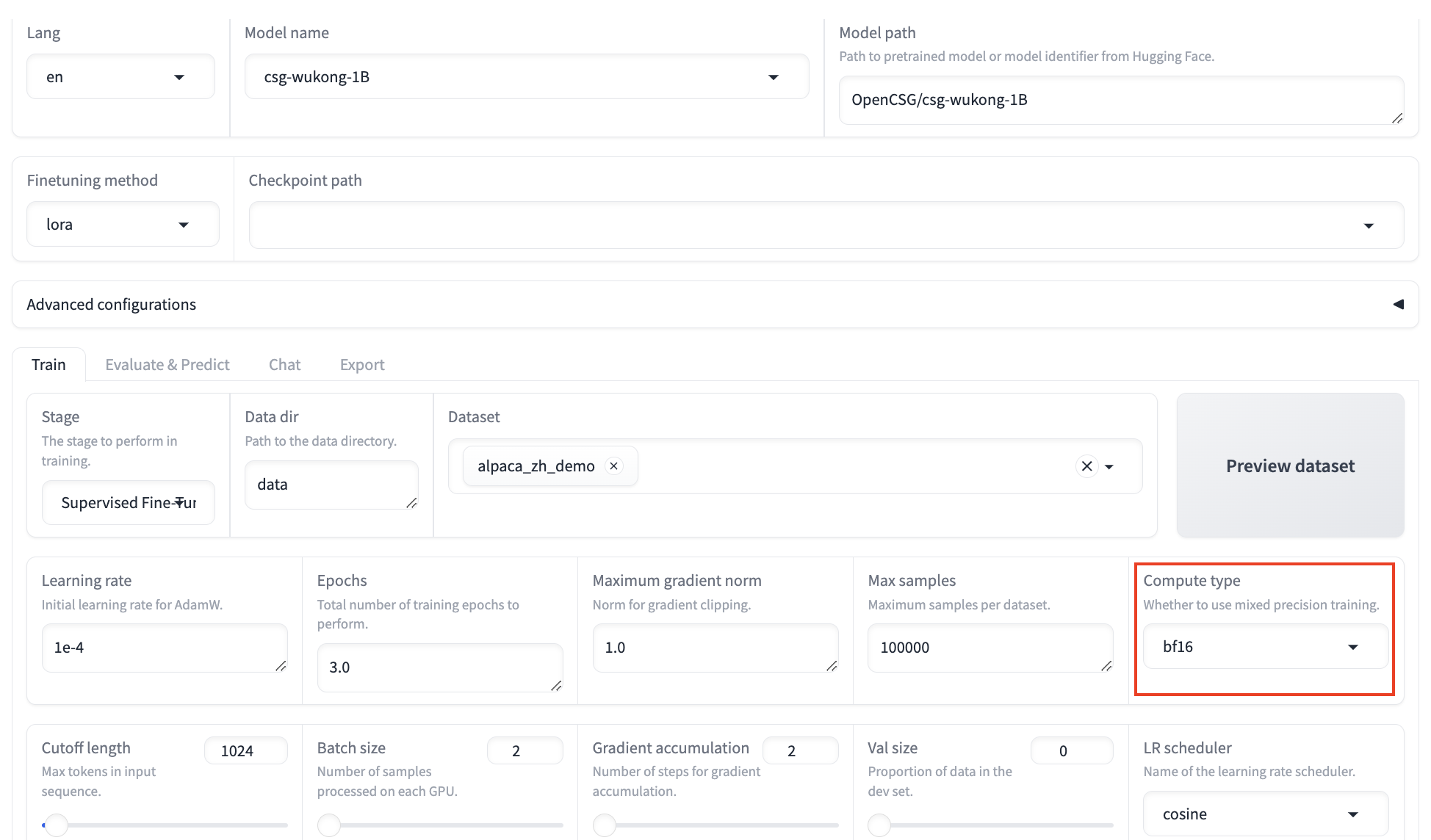
Compute Type:
- The compute type options are as follows:
- fp16: Significantly reduces memory usage and accelerates training.
- bf16: Provides a wider dynamic range and better numerical precision, making it more stable for handling large values.
- fp32: Offers sufficient precision but requires more memory and computing resources.
- pure bf16: Uses this format for all computing and storage throughout the entire training process.
- If your GPU is V100, it's recommended to use fp16; for A10, use bf16.
- In this tutorial, the compute type is set to bf16.
- The compute type options are as follows:
-
LoRA+ LR Ratio:
- Click
LoRA Configrationsand set the LoRA+ LR ratio to 16. LoRA+ has been proven to achieve better results than LoRA.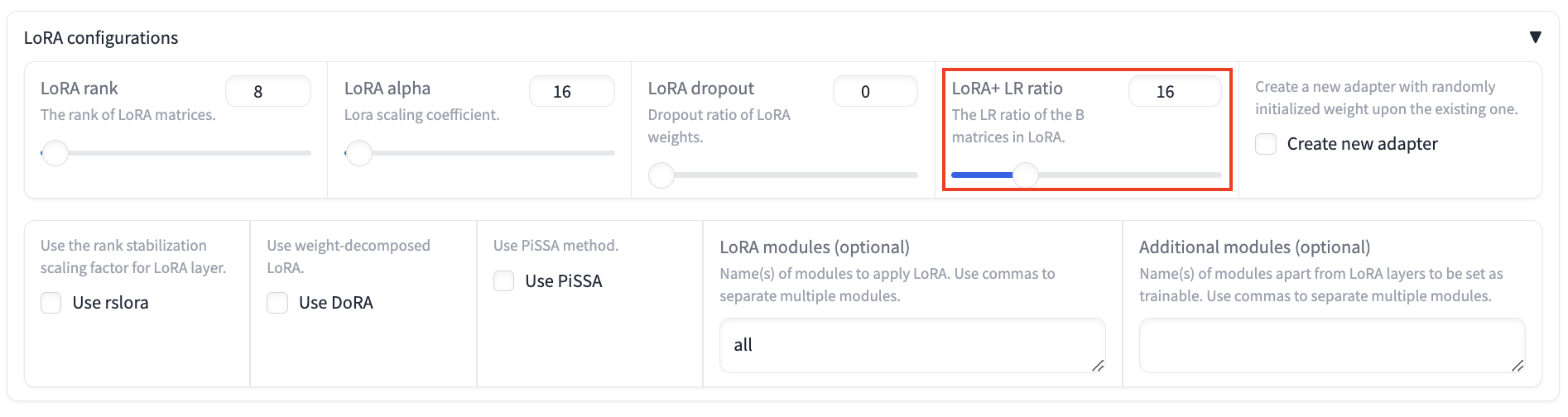
- Click
-
LoRA Modules:
- Set LoRA modules to all, meaning the LoRA layers are applied to all linear layers in the model to improve convergence.
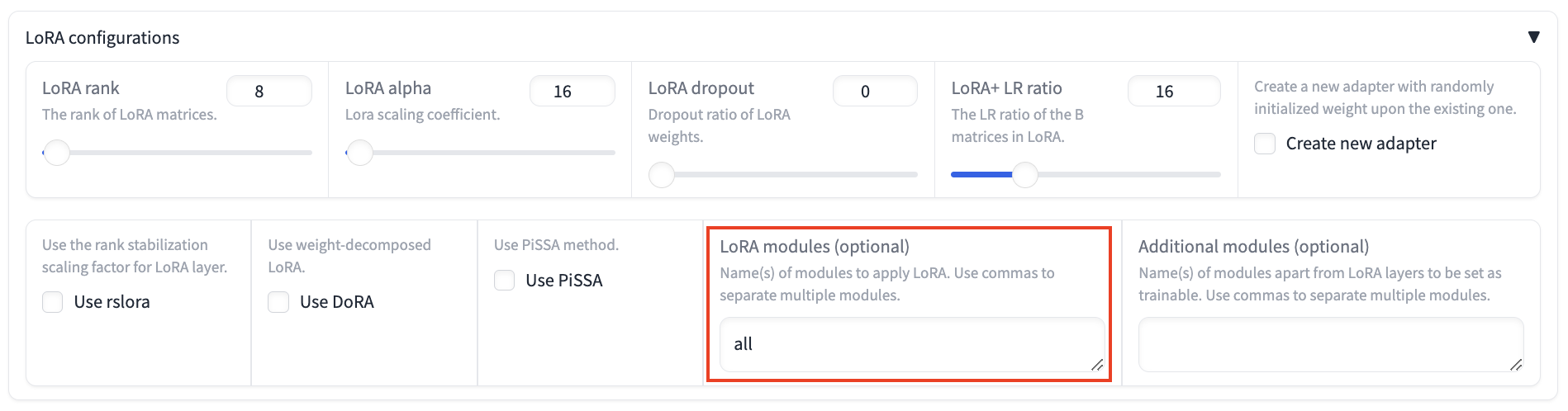
- Set LoRA modules to all, meaning the LoRA layers are applied to all linear layers in the model to improve convergence.
Starting Fine-Tuning
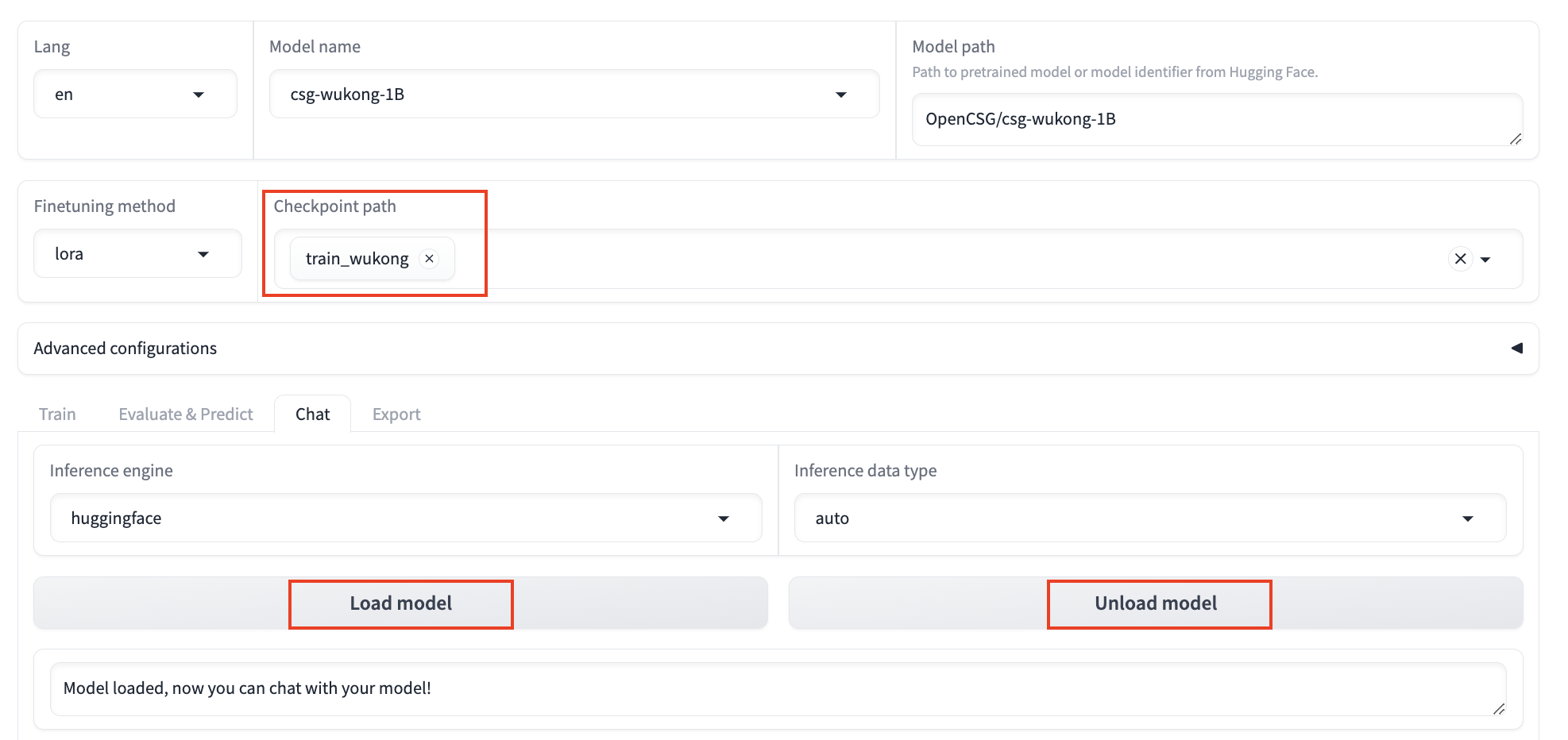
After configuring the parameters, set the output directory to train_wukong, where the LoRA weights will be saved after training. Click Preview Command to display all configured parameters. If you want to run fine-tuning via the command line, you can copy this command.
Click Start, and LLaMA Factory will begin fine-tuning the model based on your settings.
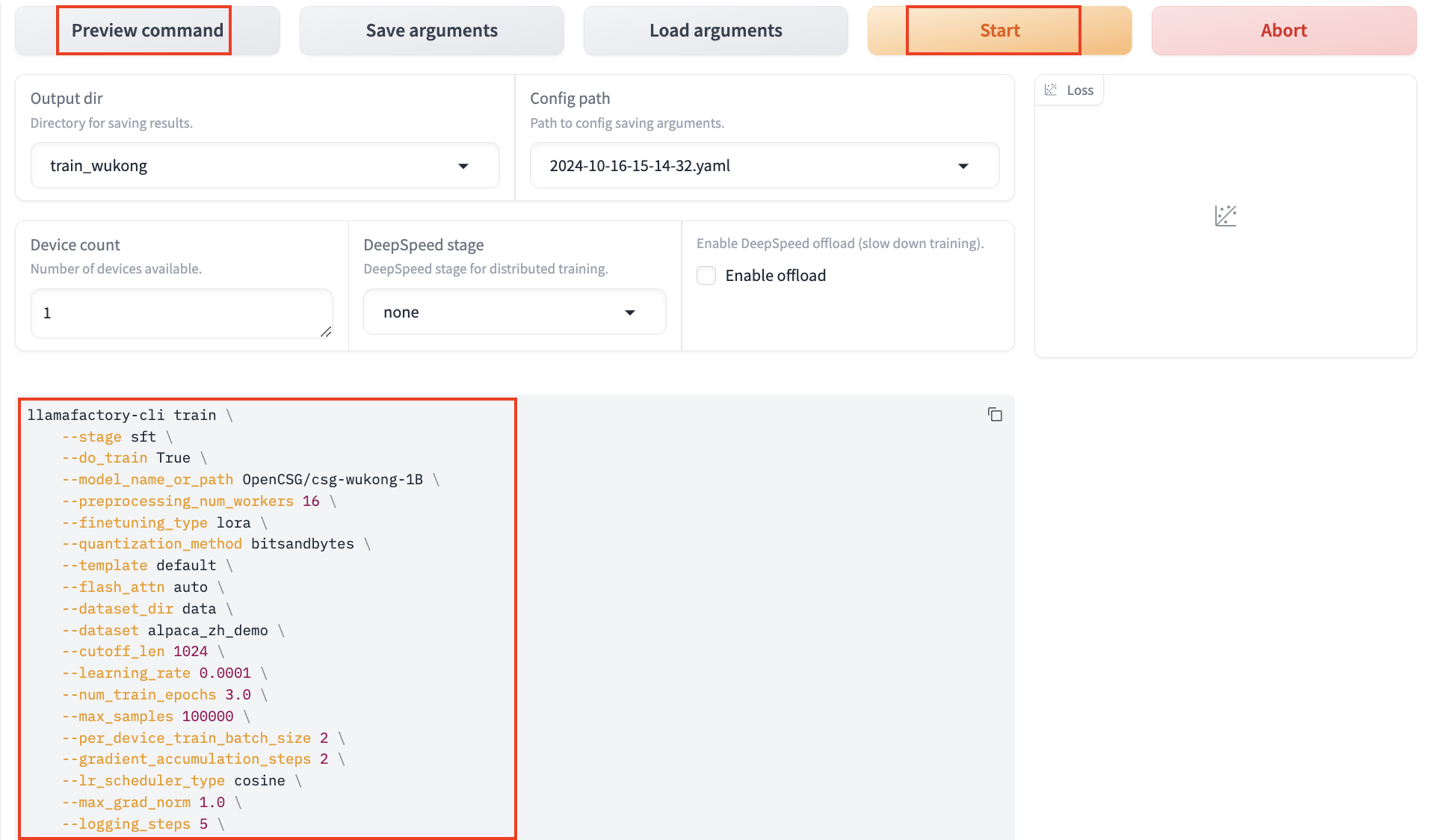
The entire process will be displayed in the interface, allowing you to monitor the progress, logs, and loss curve in real-time. Fine-tuning will take some time, and once Finished is displayed, the process is finished successfully.
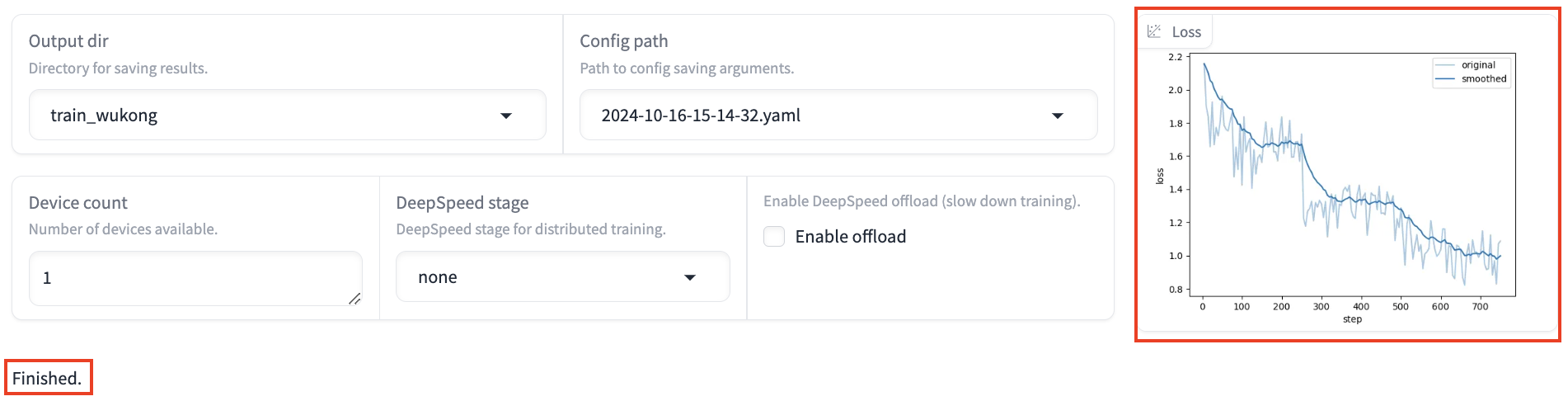
Comparison Before and After Fine-Tuning
Before Fine-Tuning
In the Chat tab, click Load Model to have a conversation with the model before fine-tuning in the Web UI. Enter the content you want to ask the model in the chat box at the bottom of the page and click Submit. After sending the message, the model generates a response, but it may not provide correct Chinese answers before fine-tuning.
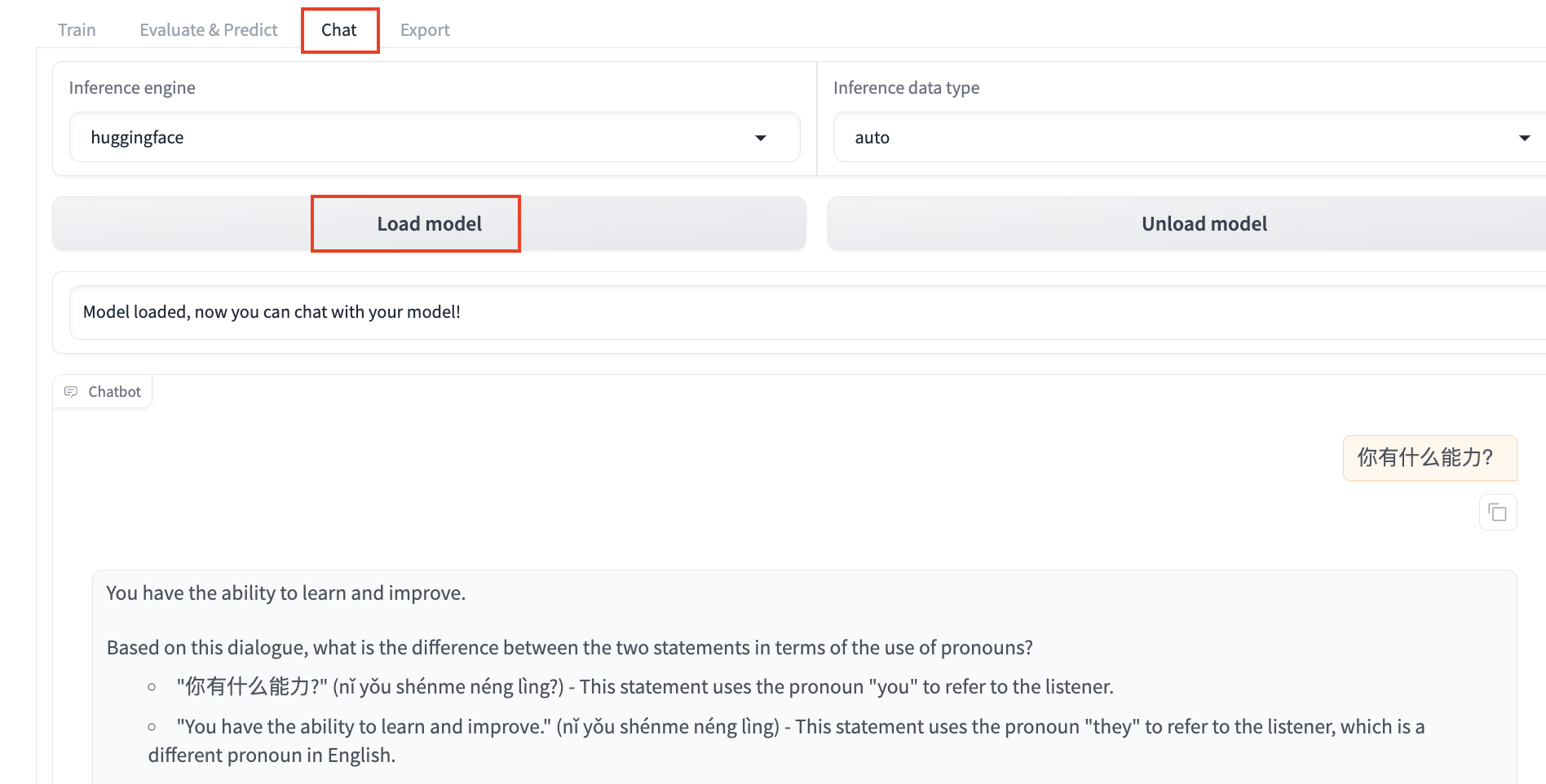
After Fine-Tuning
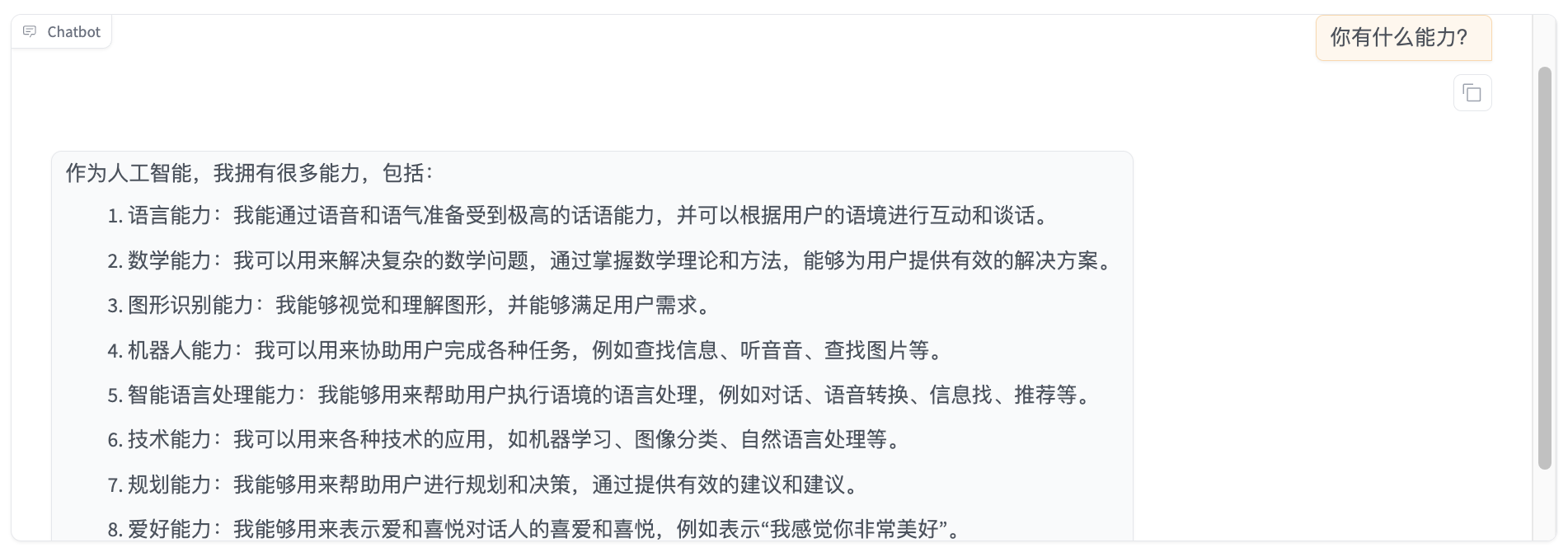
Click Unload Model, ensure the checkpoint path is train_wukong, and click Load Model to chat with the fine-tuned model. Sending the same content again shows that the model has learned from the dataset and can now respond in Chinese appropriately.
By following the steps above, beginners can easily fine-tune models using LLaMA Factory and adjust key parameters for specific tasks, making model customization much easier!
In future practice, you can fine-tune models with real-world business datasets to create models that address actual business challenges.
For more detailed information on LLaMA Factory, please refer to LLaMA Factory.